Table of Contents
- 1. General Information
- 2. Installation
- 3. Using SourceBuilder - Tutorial on Multiple Database Querying
- Using the Sample Databases
- Data Virtualization Using SourceBuilder
- Multiple Database Virtualization and Querying for HSQLDB
- Multiple Database Virtualization and Querying for IBM DB2
- Multiple Database Virtualization and Querying for Microsoft SQL Server
- Multiple Database Virtualization and Querying for MySQL
- Multiple Database Virtualization and Querying for Oracle
- Multiple Database Virtualization and Querying for PostgreSQL
- Multiple Database Virtualization and Querying for Sybase
- Multiple Database Virtualization and Querying for MongoDB
- Multiple Database Virtualization and Querying for Other JDBC/ODBC Sources
- 4. Multiple Database Programming with UnityJDBC
- 5. Using UnityJDBC with Query and Reporting Software
- 6. Supported SQL Syntax
- 7. Supported JDBC Methods
- 8. UnityJDBC Driver Internals
- 9. History and Planned Features
List of Tables
Table of Contents
UnityJDBC is a Type 4 JDBC driver capable of querying multiple databases in a single SQL query. The driver can be used similar to other JDBC drivers including with query, reporting, and business intelligence tools, application and web servers, or stand-alone Java programs. Internally, UnityJDBC contains a database engine and optimizer allowing it to efficiently join data from source databases to produce a single ResultSet. UnityJDBC supports updating data using results produced from cross-database queries and performs automatic dialect translation to convert queries into the proper dialect. A brief list of the major supported features is below:
-
supports cross-database joins of any number or type of JDBC-accessible sources (Microsoft SQL Server, Oracle, DB2, Postgres, MySQL, Sybase, MongoDB, Splunk, ServiceNow, Cassandra, etc.)
-
allows SQL-based comparison of data across databases to detect data inconsistencies, errors, or for synchronization of data between databases
-
performs SQL dialect translation and automatically executes functions and features internally in the driver if the data source does not support them
-
contains an advanced optimizer and query processor that performs efficient query processing by having each source process as much of the query as possible (e.g. "push-down filters")
-
cross-database queries can be used to insert records into tables (INSERT INTO ... SELECT)
-
supports cross-database PreparedStatements
-
has a driver by-pass feature to allow direct access to individual sources
-
supports connection pools and connection properties
-
supports user-defined functions
-
works with any data source that has a JDBC driver and will run on any Java supported platform
-
works with all SQL query software including SQuirreL SQL, Aqua Data Studio, Toad, and RazorSQL
-
works will business intelligence and reporting software including Tableau, JasperReports, Pentaho, and Splunk
Table of Contents
The free evaluation version of UnityJDBC is a fully functioning system. The only constraint with the evaluation version is that it will only produce the first 100 results in a ResultSet. The full version has no restrictions. The evaluation version can be downloaded at https://www.unityjdbc.com/download.php. You are free to distribute the evaluation version of the software.
UnityJDBC requires a JRE of 1.6 or higher. UnityJDBC will run on a J2SE or J2EE platform.
UnityJDBC can be downloaded, installed, tested, and configured for your environment in less than 10 minutes. Here are the easy steps:
-
Downloading - First, download the UnityJDBC package to your computer from https://www.unityjdbc.com/download.php.
-
Installation - The UnityJDBC installation package contains the driver, a simple query GUI, and some test programs. The
UnityJDBC_Trial_Install.jarcan be run by typing the command:java -jar UnityJDBC_Trial_Install.jar. Follow the prompts to install UnityJDBC on your machine. -
Quick Start - The installation creates a shortcut to the UnityJDBC SourceBuilder which is a simple graphical query editor and configuration tool. You can also run it directly using
initsources.batorinitsources.shin the installation directory. To try the sample queries, you will also want to click on the Start Database shortcut or run the scriptstartDB.batorstartDB.shin the directorysampleDB/hsqldb. Below is a screenshot of running a sample query that joins across two databases.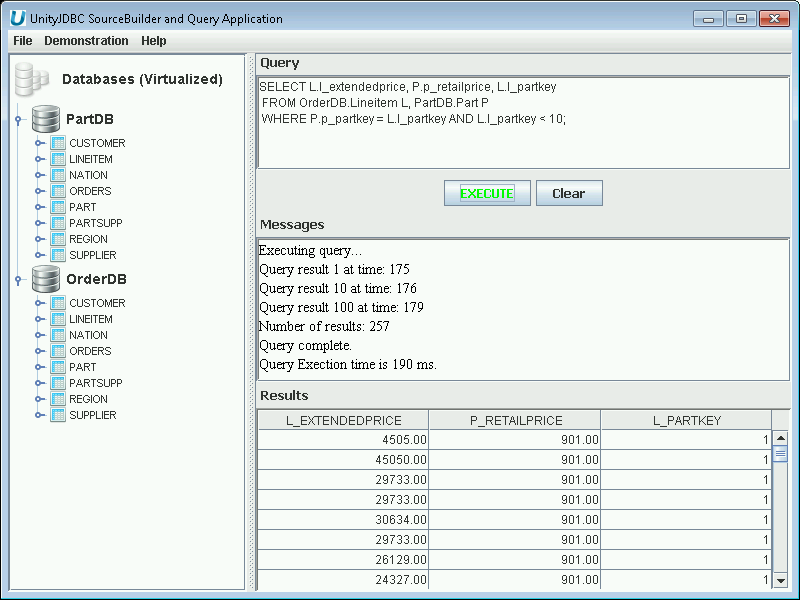
Multiple Database Query Example
-
Writing queries - UnityJDBC uses the standard SQL language. You can include as many databases in the virtual database that you wish. To reference a table in a given database, prefix it with the database name. In the example above, OrderDB.Lineitem refers to the Lineitem table in OrderDB (a user-assigned name for the sample HSQL database), and PartDB.Part refers to the Part table in the PartDB database. Writing queries is as easy as prefixing the table name with the database name!
-
Creating Your Own Virtual Database - A virtual database is defined using a sources XML file, often with the default filename of
sources.xml. Each database also has a schema file storing information on its tables and fields. These XML files are automatically built by SourceBuilder, but can also be edited directly at any time. A few quick steps to produce your own virtual database:-
Select
File->New Source Groupand use the defaultsources.xmlfile. -
Select
File->New Sourceand provide the JDBC connection information for your source. The screenshots below show MySQL and PostgreSQL.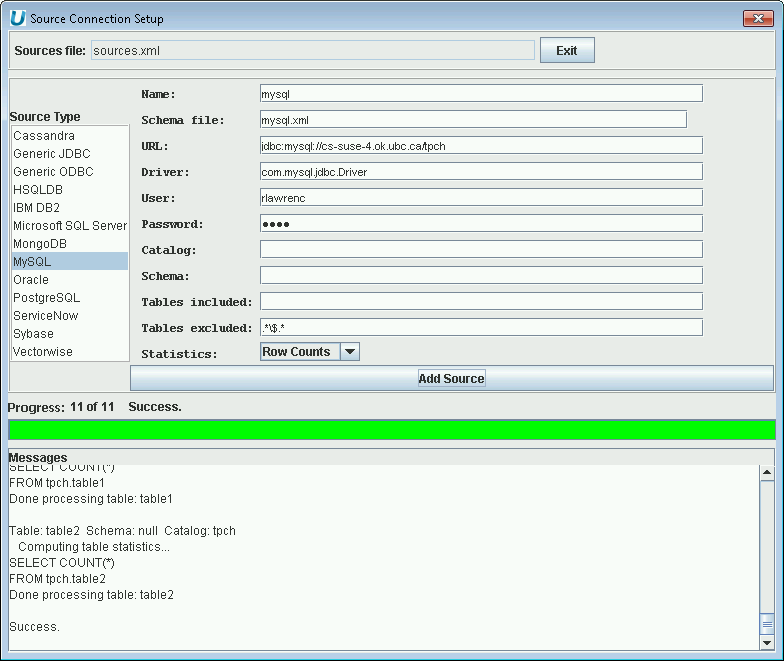
Multiple Database Virtualization - Adding MySQL Database
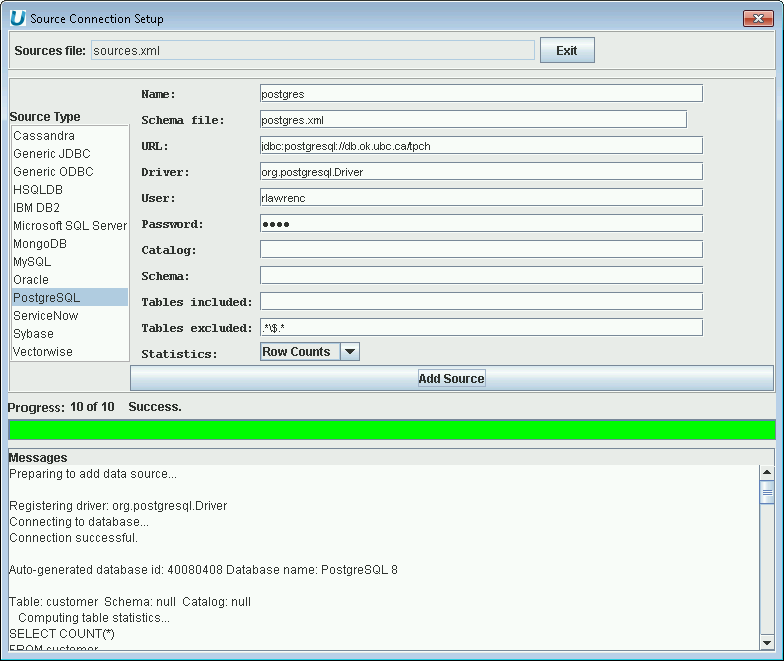
Multiple Database Virtualization - Adding PostgreSQL Database
-
Write a query that can join across multiple databases. The only difference from standard SQL is that you prefix the table name with the database name.
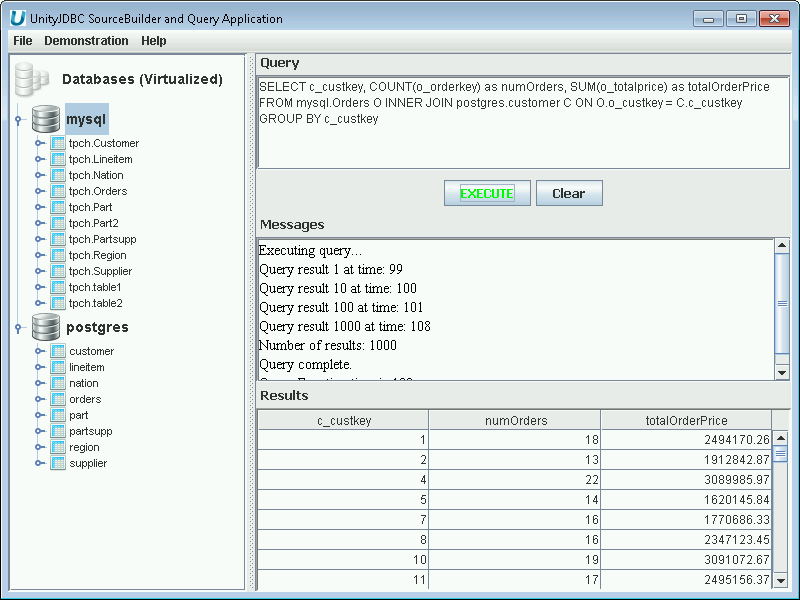
Multiple Database Query Example that Joins Table in MySQL with a Table in PostgreSQL
-
After creating your virtual database, you will have one
sources.xmland an XML schema file for each database. These files can be moved to any location and are used to configure UnityJDBC when using it with other applications.
-
-
Using UnityJDBC - Now that a virtual database is created, there are three general steps to using UnityJDBC common in all cases.
-
Move the
sources.xmland the XML schema files for the databases into a desired directory. For this example, the directory is/unityjdbc. -
Put the
unityjdbc.jarinto yourCLASSPATHas well as the drivers for each database. (Some drivers are included with the UnityJDBC distribution in the directorydriversin the installation folder.) A common location is in<JAVA_HOME>/jre/lib/ext. -
The connection information is the UnityJDBC driver class
unity.jdbc.UnityDriverand the URL isjdbc:unity://<relative or absolute path to sources file>such asjdbc:unity://unityjdbc/sources.xml.
The UnityJDBC driver can be used with any software that supports JDBC. A screenshot of configuring it in Aqua Data Studio is below. The same connection information applies to all JDBC-based software.
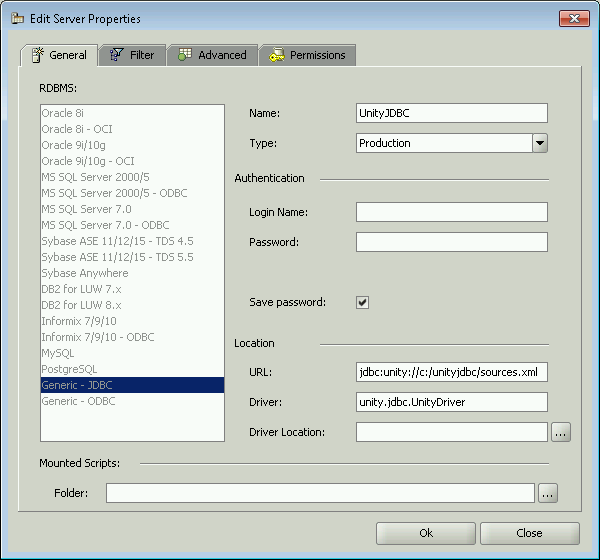
Registering the UnityJDBC Driver in Aqua Data Studio
UnityJDBC can also be used with your own Java programs. There is sample code in the
codedirectory in the installation folder. Here are two commands (executed from thecodedirectory) to compile and run the sample code:javac test/ExampleQuery.javajava test.ExampleQueryIf you have issues with compiling or running, try to explicitly indicate the location of the UnityJDBC JAR:
javac -cp .;../unityjdbc.jar;../sampleDB/hsqldb/hsqldb.jar test/ExampleQuery.javajava -cp .;../unityjdbc.jar;../sampleDB/hsqldb/hsqldb.jar test.ExampleQueryTo create your own Java program, copy the file
ExampleQuery.javatoMyQuery.java. There are 2 lines that you must modify. The first line indicates where your new sources XML file is located on your machine. You may specify an absolute or relative path from the current directory. The second line you must modify is to change the SQL query to reference fields and tables in your data source(s). Compile and run the program. Queries can reference any table or field in any data source in your XML sources file as long as you prefix a table or field with the database name such asMyDB.MyTable.MyField. -
Once you have downloaded UnityJDBC from https://www.unityjdbc.com/download.php,
you will have downloaded a JAR file called UnityJDBC_Trial_Install.jar.
First, you need to have Java previously installed in order to
install UnityJDBC. Then, you can install UnityJDBC by either double-clicking
the JAR file or running the following command: java -jar
UnityJDBC_Trial_Install.jar. The installation steps are below.
-
Welcome Screen - Provides some background on UnityJDBC. Click Next.
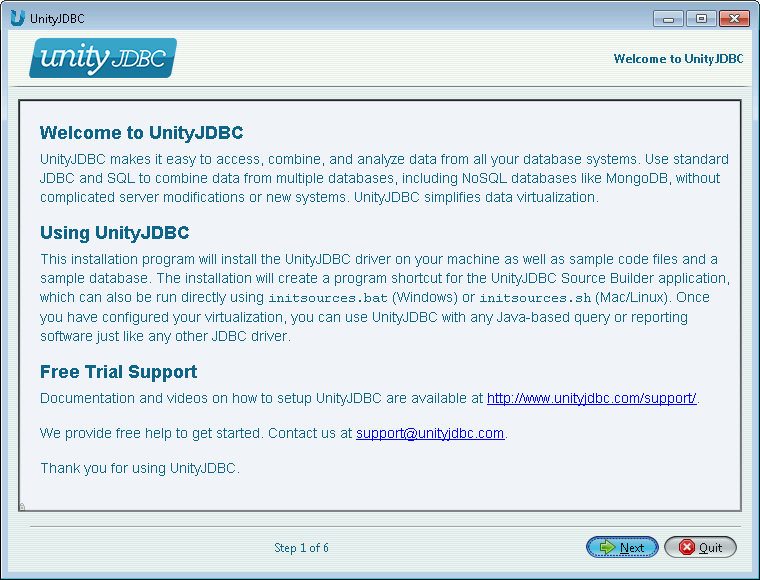
UnityJDBC Installation Part #1 - Welcome Screen
-
End-User License Agreement - Read the EULA, select Accept, and click Next.
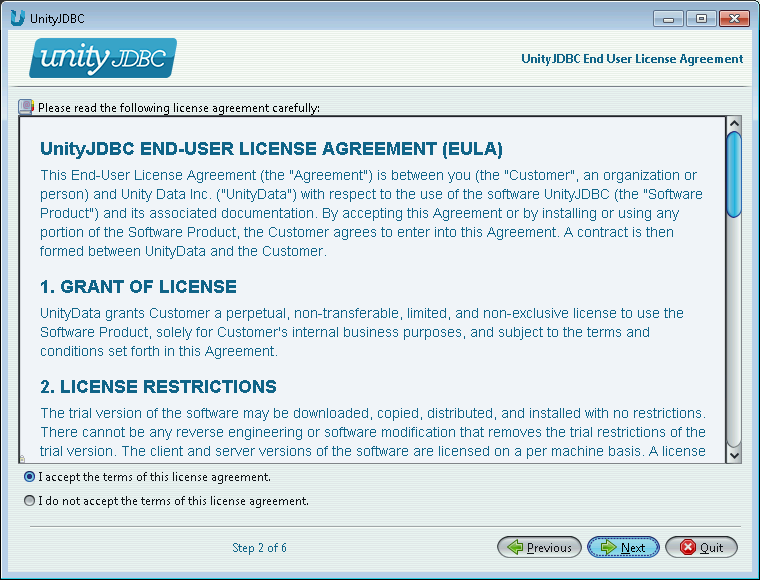
UnityJDBC Installation Part #2 - End-User License Agreement
-
Install Path - Select the installation path for UnityJDBC and then click Next.
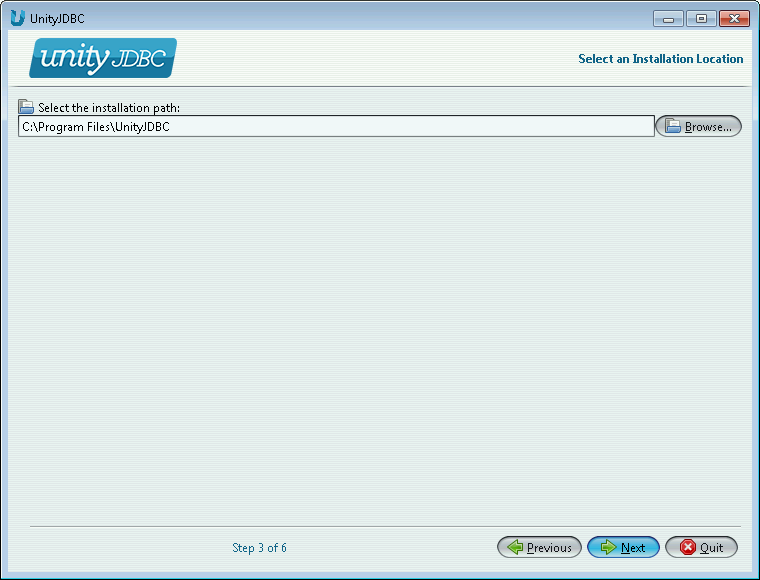
UnityJDBC Installation Part #3 - Select Installation Path
-
Install Progress - The installation will be performed and progress shown. Click Next when complete.
UnityJDBC Installation Part #4 - Installation Progress
-
Install Shortcuts - The installation will install shortcuts to start SourceBuilder and a sample database. This screen allows you to control if shortcuts are created and their location. When finished, click Next.
UnityJDBC Installation Part #5 - Select Shortcuts
-
Installation Complete - The installation complete screen will be displayed if the installation is successful. UnityJDBC SourceBuilder will be automatically started. Click Done to close the install window.
UnityJDBC Installation Part #6 - Installation Complete
UnityJDBC will auto-start at the completion of the installation. If it does not, click
on the shortcut created. If there is no shortcut, on Windows run
initsources.bat and on Linux/Mac run
initsources.sh in the installation directory.
UnityJDBC requires information about the data sources being queried in order to
validate, optimize, and execute queries against those data sources. All source information
is stored in XML files. There are two types of source information files: the
sources file and schema files. A
sources file with default name sources.xml
provides information on all the sources that could be potentially queried. The location of
this file is provided via the URL when initializing the driver. Inside the file is
information on each source including its connection URL and parameters, JDBC driver, and
schema file location. The sample sources file
code\test\xspec\UnityDemo.xml is provided in the distribution
package. Each data source requires a schema file. The schema file is an
XML encoding of the schema information including table and field names, keys, joins, and
relation sizes. It is used for validating queries and optimization. Two schema files
provided in the distribution are: code\test\xspec\UnityDemoOrder.xml
and code\test\xspec\UnityDemoPart.xml.
There are two ways to create your own sources file and associated schema files:
-
The easiest way is to use the SourceBuilder GUI that can be started using the installed shortcut or running
initsources.batorinitsources.sh. This GUI will automatically extract source information and build the necessary files. If you are using UnityJDBC as the multisource plugin in SQuirreL SQL, all features of the SourceBuilder are integrated into SQuirreL, and the XML files are generated automatically. -
You can manually build a sources file using a text editor. To produce a schema file for a source, open up the program called
com/unityjdbc/SourceBuilder/SchemaExtractor.javain thecodedirectory. Modify the JDBC URL, driver path, and output directory accordingly and run the program. The account that you connect with must have read access to the database and associated tables that you want to access. After the XML schema file has been produced, move it to the directory where you want it and update the sources file to reference the correct location. In almost all cases, using the SourceBuilder utility will be faster and easier.
Table of Contents
- Using the Sample Databases
- Data Virtualization Using SourceBuilder
- Multiple Database Virtualization and Querying for HSQLDB
- Multiple Database Virtualization and Querying for IBM DB2
- Multiple Database Virtualization and Querying for Microsoft SQL Server
- Multiple Database Virtualization and Querying for MySQL
- Multiple Database Virtualization and Querying for Oracle
- Multiple Database Virtualization and Querying for PostgreSQL
- Multiple Database Virtualization and Querying for Sybase
- Multiple Database Virtualization and Querying for MongoDB
- Multiple Database Virtualization and Querying for Other JDBC/ODBC Sources
SourceBuilder is a graphical query tool that allows you to define a virtual database
consisting of multiple databases including MySQL, PostgreSQL, Oracle, Microsoft SQL Server,
Sybase, MongoDB, and others. SourceBuilder can be started using the shortcut produced during the
installation, by running initsources.bat or
initsources.sh in the installation folder, or directly from the
driver using the command java -jar unityjdbc.jar. It is required that
the unityjdbc.jar and all JDBC driver JAR files for databases used be
in the Java classpath.
When SourceBuilder is first started, a welcome screen is displayed.
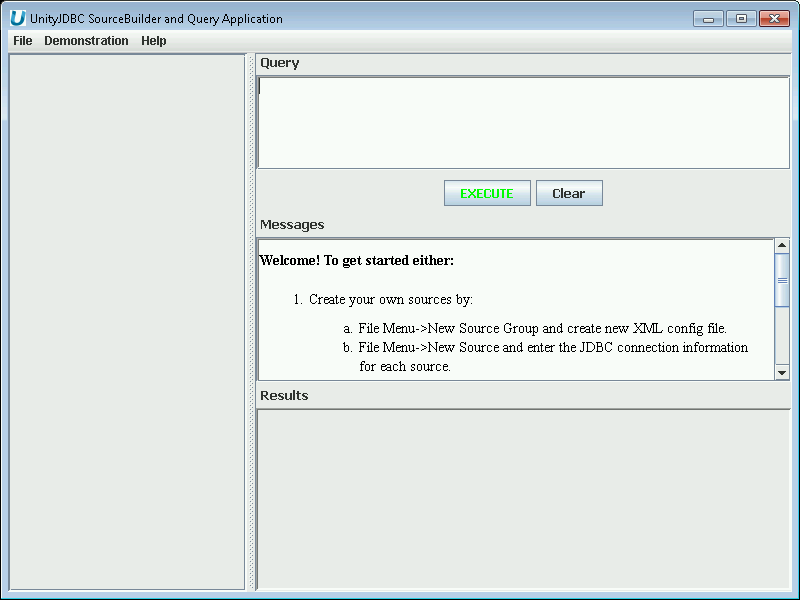 |
SourceBuilder Welcome Screen
To use the sample database and queries included, make sure to start the HSQLDB using the
Start Database shortcut or run the script startDB.bat or
startDB.sh in the directory sampleDB/hsqldb. Then,
select Demonstration->Cross-database Join Test. Click the
EXECUTE button to run the query and get results. If an error occurs,
verify that the sample database is started and the hsqldb.jar file is in
your classpath. You can try several other of the sample queries or write your own.
|
SourceBuilder Multiple Database Query Example with a Cross-Database Join
To build your own data virtualization of multiple data sources, create a new sources
file by selecting File->New Source Group and providing a file name
(the default is sources.xml).
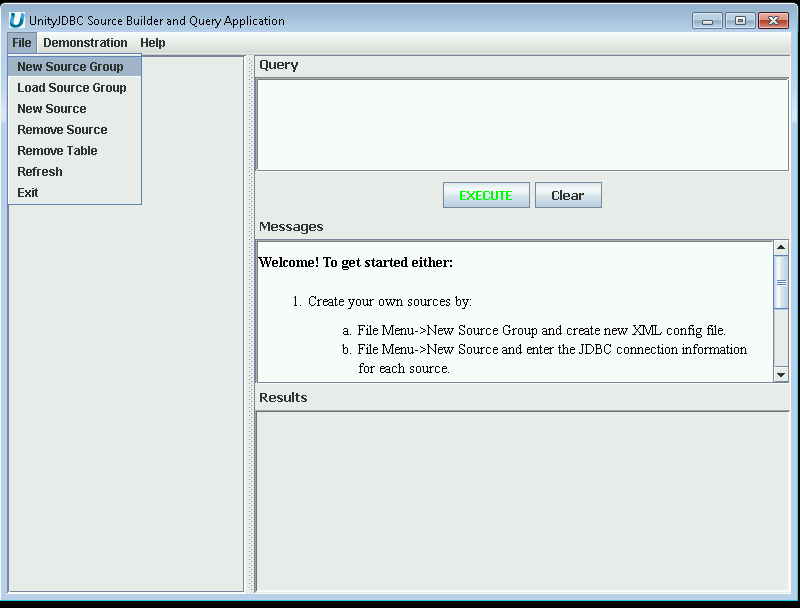 |
Creating a New Source Group with SourceBuilder
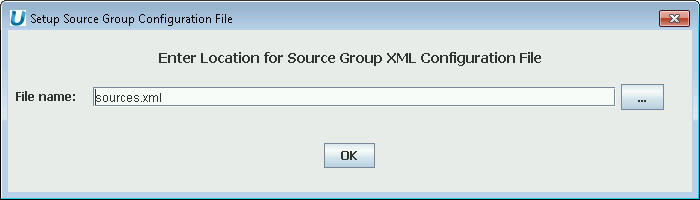 |
Prompt for Name of Sources File
Then, you will add each one of your sources by providing its JDBC connection information. To add a source you need the following information:
-
The JDBC Driver class name (e.g.
com.mysql.jdbc.Driver). -
The JDBC URL to connect to the source (e.g.
jdbc:mysql://localhost/mydb). -
User and password information if not specified in the JDBC URL.
-
A unique database name (does not have to be the same as the system database name) to refer to the data source in your data virtualization.
An example of adding a MySQL source to the virtual database is below.
|
Adding a MySQL Data Source to the Data Virtualization
There are also several additional features that can be used to control the extraction.
-
Schema - Specify a schema name or pattern (JDBC API) to only retrieve tables in the given schema. This is especially important for Oracle as by default tables from all schemas will be added to the virtualization.
-
Tables included - Specify a JDBC API pattern (use % for wild card character match) to indicate which tables should be added to the extraction. For example, a pattern of
R%will only add tables that begin withR. -
Tables excluded - Specify a Java string pattern (use .* for matching any sequence of characters) to indicate what tables to exclude from extraction. Each database has certain default exclusion patterns to avoid extracting system tables. It is recommended to modify the exclusion pattern if there are any issues extracting too many tables, especially system tables for your data source.
-
Statistics - Statistics collection helps the UnityJDBC optimizer perform more efficient data virtualization queries. The default statistics collection is
Row Countswhich will calculate the number of rows for each extracted table. TheAllstatistics setting collects rows counts as well as value distribution information for each field. Some sources do not support collecting field distribution information in which case theRow Countssetting should be used. A setting ofNonewill collect no statistics and is the fastest when performing extraction. UnityJDBC will execute queries with no statistics perfectly fine, although statistics do help in query planning for complex queries involving many tables.
Below is an example of extracting only the tables that end in 'ER' from an Oracle
database. Note how the schema is also supplied as RLAWRENC.
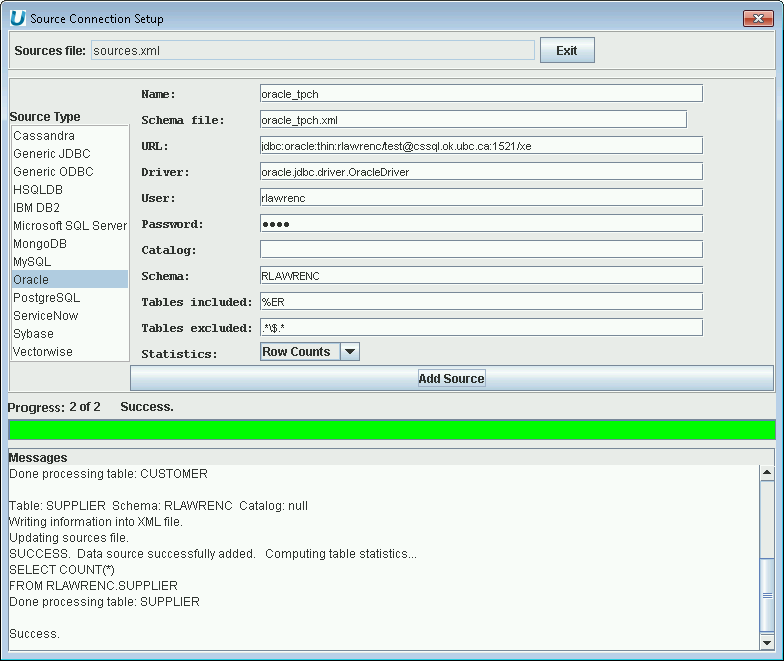 |
Adding an Oracle Data Source to the Data Virtualization (note use of schema name)
Using UnityJDBC SourceBuilder, it is possible to build a data virtualization of one or more HSQLDB databases with any other database system. To add a HSQLDB data source, the following information is used:
-
JDBC Driver class name:
org.hsqldb.jdbcDriver. -
JDBC URL:
jdbc:hsqldb:hsql://<host address>/<database name>.
An example of adding a HSQLDB source to a data virtualzation is below.
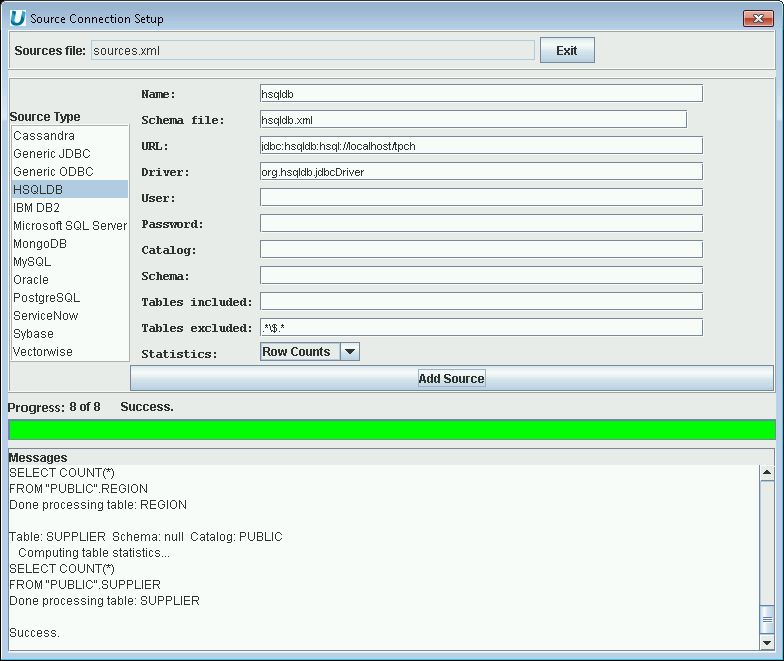 |
Adding a HSQLDB Data Source to the Data Virtualization
Using UnityJDBC SourceBuilder, it is possible to build a data virtualization of one or more IBM DB2 databases with any other database system. To add an IBM DB2 data source, the following information is used:
-
JDBC Driver class name:
com.ibm.db2.jcc.DB2Driver. -
JDBC URL:
jdbc:db2://<host name>/<database name>.
An example of adding an IBM DB2 source to a data virtualzation is below.
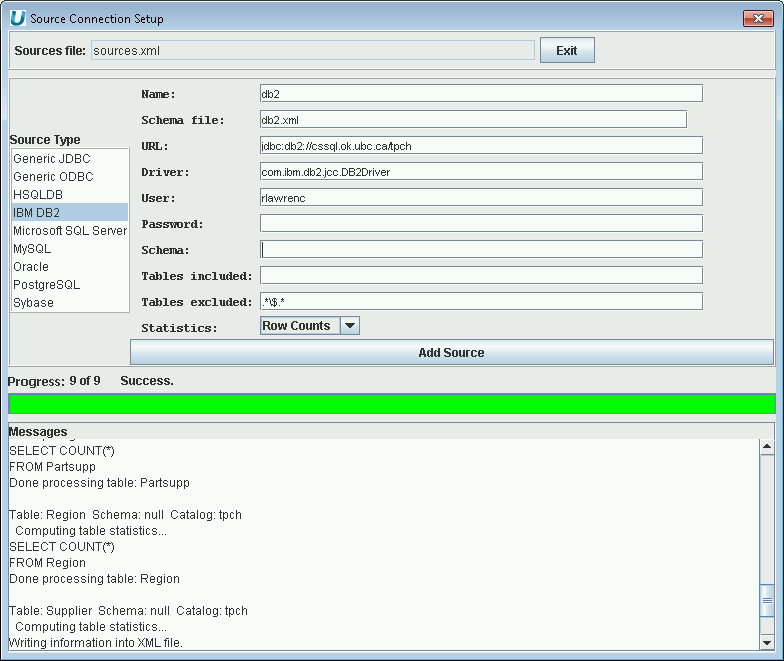 |
Adding an IBM DB2 Data Source to the Data Virtualization
Using UnityJDBC SourceBuilder, it is possible to build a data virtualization of one or more Microsoft SQL Server databases with any other database system. To add a Microsoft SQL Server data source, the following information is used:
-
JDBC Driver class name:
com.microsoft.sqlserver.jdbc.SQLServerDriver. -
JDBC URL:
jdbc:sqlserver://<host>;DatabaseName=<database name>.
An example of adding a Microsoft SQL Server data source to a data virtualzation is below.
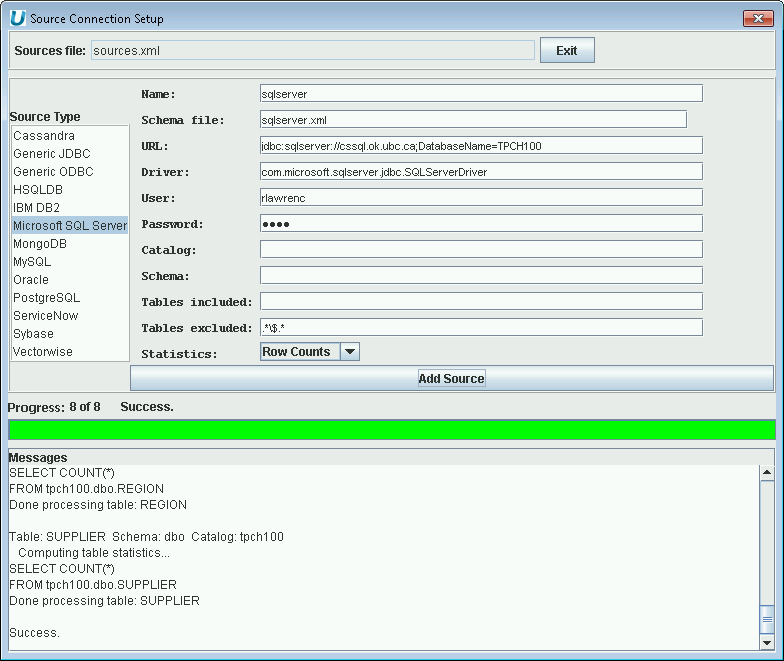 |
Adding a Microsoft SQL Server Data Source to the Data Virtualization
Using UnityJDBC SourceBuilder, it is possible to build a data virtualization of one or more MySQL databases with any other database system. To add a MySQL data source, the following information is used:
-
JDBC Driver class name:
com.mysql.jdbc.Driver. -
JDBC URL:
jdbc:mysql://<host address>/<database name>.
An example of adding a MySQL source to a data virtualzation is below.
|
Adding a MySQL Data Source to the Data Virtualization
Using UnityJDBC SourceBuilder, it is possible to build a data virtualization of one or more Oracle databases with any other database system. To add an Oracle data source, the following information is used:
-
JDBC Driver class name:
oracle.jdbc.driver.OracleDriver. -
JDBC URL:
jdbc:oracle:thin:<user>/<password>@<server>:1521/<service>.
An example of adding an Oracle data source to a data virtualzation is below.
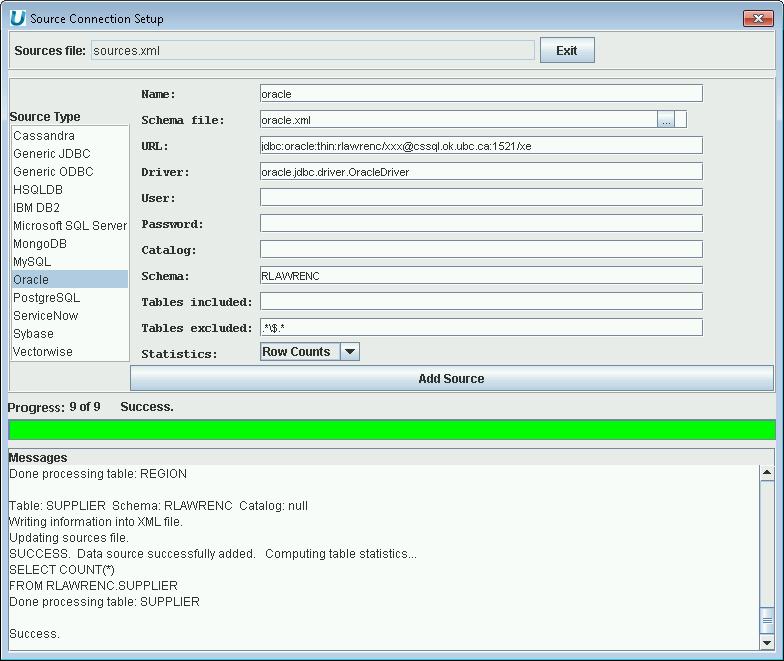 |
Adding an Oracle Data Source to the Data Virtualization
Using UnityJDBC SourceBuilder, it is possible to build a data virtualization of one or more PostgreSQL databases with any other database system. To add a PostgreSQL data source, the following information is used:
-
JDBC Driver class name:
org.postgresql.Driver. -
JDBC URL:
jdbc:postgresql://<server>/<database>?user=<userId>&password=<password>.
An example of adding a PostgreSQL source to a data virtualzation is below.
|
Adding a PostgreSQL Data Source to the Data Virtualization
Using UnityJDBC SourceBuilder, it is possible to build a data virtualization of one or more Sybase databases with any other database system. To add a Sybase data source, the following information is used:
-
JDBC Driver class name:
com.sybase.jdbc4.jdbc.SybDriver. -
JDBC URL:
jdbc:sybase:Tds:<server>:<port>/<database>?user=<userid>&password=<password>.
An example of adding a Sybase source to a data virtualzation is below.
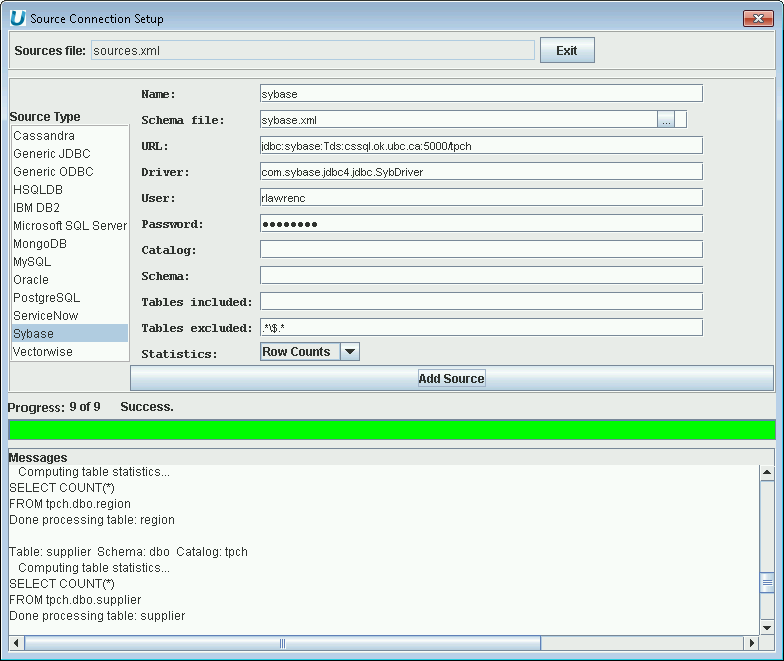 |
Adding a Sybase Data Source to the Data Virtualization
Using UnityJDBC SourceBuilder, it is possible to build a data virtualization of one or more MongoDB databases (collections) with any other database system. Note that a MongoDB JDBC driver is built into UnityJDBC and can be used separately from UnityJDBC directly. For more information go to https://www.unityjdbc.com/mongojdbc To add a MongoDB data source, the following information is used:
-
JDBC Driver class name:
mongodb.jdbc.MongoDriver. -
JDBC URL:
jdbc:mongo://<server>:1521/<database>.
An example of adding a MongoDB data source to a data virtualzation is below.
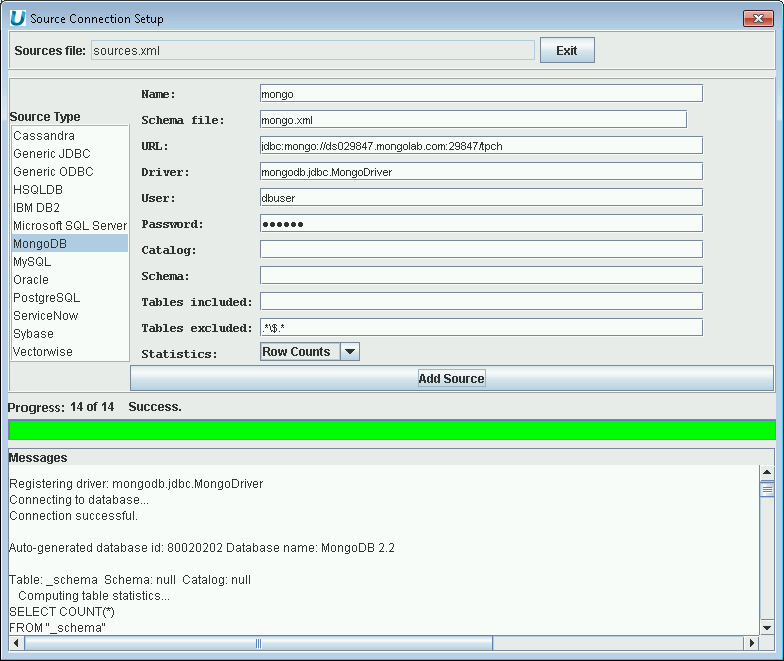 |
Adding a MongoDB Data Source to the Data Virtualization
Using UnityJDBC SourceBuilder, it is possible to build a data virtualization for any data source that supports JDBC or ODBC including Microsoft Access databases, Excel files, text files, and any data source that has a JDBC driver.
Table of Contents
UnityJDBC is a universal query translator. It allows you to develop your programs without worrying about the underlying database. All SQL statements executed with UnityJDBC are translated for the database used. Even if you do not need multiple database queries, data virtualization, or queries that span multiple different databases, UnityJDBC simplifies your development by handling all the issues with SQL dialects. If a function is not supported by your database, UnityJDBC will execute it internally. If you forget a function name for a database, it will translate to the correct function call for the particular source. This allows you the freedom to write your SQL code in a database independent way. You no longer have to make major changes to your code if you change database systems. If you want full control, you can use the UnityJDBC database engine directly in your code to join ResultSets with each other regardless of their source, and perform dynamic filtering, ordering, and analysis.
Sample programs are provided in the directory
code. Here is a list of the programs and the features
they demonstrate:
-
ExampleQuery.java- a query example that joins data across two databases -
ExampleUpdate.java- demonstratesINSERT/UPDATE/DELETEand how to store a cross-database query result into a table -
ExampleMetaData.java- query example showing how to extract metadata information -
ExampleEngine.java- an advanced example that shows how users can use the UnityJDBC database engine directly -
ExampleNoFileConnection.java- example showing how to configure UnityJDBC in code without using XML files
All of these examples use a local HSQL database that can be started using the script
startDB.bat or startDB.sh in the directory
sampleDB/hsqldb in the installation folder.
To compile and run any of these sample programs make sure you are
in the code directory and execute the following
commands:
javac test/ExampleQuery.java
java test.ExampleQuery
If you have CLASSPATH issues, you can explicitly indicate the location of the HSQL JDBC driver and the UnityJDBC driver by:
javac -cp.;../UnityJDBC.jar;../sampleDB/hsqldb/hsqldb.jar
test/ExampleQuery.java
java -cp.;../UnityJDBC.jar;../sampleDB/hsqldb/hsqldb.jar
test.ExampleQuery
The ExampleQuery.java demonstrates the
basic features of the UnityJDBC driver. The code is below.
import java.sql.*;
public class ExampleQuery
{
// URL for sources.xml file specifying what databases to integrate.
// This file must be locally accessible or available via http URL.
static String url="jdbc:unity://test/xspec/UnityDemo.xml";
public static void main(String [] args) throws Exception
{
Connection con = null;
Statement stmt = null;
ResultSet rst;
try {
// Create new instance of UnityDriver and make connection
System.out.println("\nRegistering driver.");
Class.forName("unity.jdbc.UnityDriver");
System.out.println("\nGetting connection: "+url);
con = DriverManager.getConnection(url);
System.out.println("\nConnection successful for "+ url);
System.out.println("\nCreating statement.");
stmt = con.createStatement();
// Unity supports scrollable ResultSets,
// but better performance with FORWARD_ONLY
// stmt = con.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE,
// ResultSet.CONCUR_READ_ONLY);
// A query is exactly like SQL.
// Attributes should be FULLY qualified: database.table.field
// Statement must end with a semi-colon ;
// This query performs cross-database join on the client-side
String sql =
"SELECT PartDB.Part.P_NAME, OrderDB.LineItem.L_QUANTITY,"
+ " OrderDB.Customer.C_Name, PartDB.Supplier.s_name"
+ " FROM OrderDB.CUSTOMER, OrderDB.LINEITEM, OrderDB.ORDERS,"
+ " PartDB.PART, PartDB.Supplier"
+ " WHERE OrderDB.LINEITEM.L_PARTKEY = PartDB.PART.P_PARTKEY AND"
+ " OrderDB.LINEITEM.L_ORDERKEY = OrderDB.ORDERS.O_ORDERKEY"
+ " AND OrderDB.ORDERS.O_CUSTKEY = OrderDB.CUSTOMER.C_CUSTKEY"
+ " AND PartDB.supplier.s_suppkey = OrderDB.lineitem.l_suppkey"
+ " AND OrderDB.Customer.C_Name = 'Customer#000000025';";
// Note: Client's local JVM is used to process some operations.
// For large queries, this may require setting a large heap space.
// JVM command line parameters: 0 -Xms500m -Xmx500m
// These parameters set heap space to 500 MB.
rst = stmt.executeQuery(sql);
System.out.println("\n\nTHE RESULTS:");
int i=0;
long timeStart = System.currentTimeMillis();
long timeEnd;
ResultSetMetaData meta = rst.getMetaData();
System.out.println("Total columns: " + meta.getColumnCount());
System.out.print(meta.getColumnName(1));
for (int j = 2; j <= meta.getColumnCount(); j++)
System.out.print(", " + meta.getColumnName(j));
System.out.println();
while (rst.next()) {
System.out.print(rst.getObject(1));
for (int j = 2; j <= meta.getColumnCount(); j++)
System.out.print(", " + rst.getObject(j));
System.out.println();
i++;
}
timeEnd = System.currentTimeMillis();
System.out.println("Query took: "+
((timeEnd-timeStart)/1000)+" seconds");
System.out.println("Number of results printed: "+i);
stmt.close();
System.out.println("\nOPERATION COMPLETED SUCCESSFULLY!");
}
catch (SQLException ex)
{ System.out.println("SQLException: " + ex);
}
finally
{
if (con != null)
try{ con.close(); }
catch (SQLException ex)
{ System.out.println("SQLException: " + ex); }
}
}The UnityJDBC driver behaves exactly like other JDBC drivers. The basic steps for querying a database with a JDBC driver are:
-
Load the driver (optional) - This is done by
Class.forName("unity.jdbc.UnityDriver"); -
Make a connection - A connection is made to a database by providing the database URL and other properties including user id and password. This example is using the
DriverManagerto make the connection (con = DriverManager.getConnection(url);). Note that the URL is of the formjdbc:unity://<path_to_sources_file>. In this case, the URL isjdbc:unity://test/xspec/UnityDemo.xml.This path may be an absolute or relative path on the machine. It is also possible to retrieve encrypted XML files from a network source. The sources file provides the connection information for the individual data sources for use by UnityJDBC. -
Execute a statement - UnityJDBC follows the JDBC API for creating statements and executing queries and updates. There are some methods unique to UnityJDBC which are covered in a later section. Standard SQL syntax is supported. The major difference is that tables in different databases can be referenced in the same query. This is accomplished using the syntax
database.tableto refer to tables anddatabase.table.fieldto refer to fields. (Note that aliasing usingASis supported.) If full names are not provided, UnityJDBC will attempt to match as appropriate, but it will generate errors if the provided names are not unique.
This file is a good one to modify to start your own program. Simply change the class and file name, the URL to the location of your source list file, and the query executed, and you are done.
UnityJDBC natively supports INSERT, UPDATE, and
DELETE statements on a single database. These statements can be
executed in by-pass mode in which case UnityJDBC does not parse or validate the statement
and passes it straight to the JDBC driver for the corresponding database. In native mode,
UnityJDBC will parse and validate the statement before passing it to the data source. Note
that the basic INSERT, UPDATE, and
DELETE statements operate only on a single table in SQL, so no
cross-database query processing is necessary. A sample of the code in
ExampleUpdate.java is
below.
Class.forName("unity.jdbc.UnityDriver");
con = DriverManager.getConnection(url);
stmt = con.createStatement();
// Example #1: Basic query
String sql = "SELECT * FROM mydb.Customer;";
rst = stmt.executeQuery(sql);
printResult(rst);
// Example #2: DELETE using native parsing
String databaseName = "mydb";
sql = "DELETE FROM mydb.customer WHERE id = 51 or id=52;";
stmt.executeUpdate(sql);
// Example #3: INSERT (by-pass method)
sql = "INSERT INTO Customer (id,firstname,lastname,street,city) "
+ " VALUES (51,'Joe','Smith','Drury Lane', 'Detroit')";
((UnityStatement) stmt).executeByPassQuery(databaseName,sql);
// Example #4: INSERT - Unity Parsed
sql = "INSERT INTO mydb.Customer (id, firstname, "
+ " lastname, street, city) "
+ " VALUES (52,'Fred','Jones','Smith Lane', 'Chicago');";
stmt.executeUpdate(sql);
// Example #5: INSERT INTO (SELECT...) across databases
sql = "INSERT INTO emptydb.customer (SELECT * FROM mydb.customer);";
stmt.executeUpdate(sql);
// Prove that we transferred the data
sql = "SELECT * FROM emptydb.Customer;";
rst = stmt.executeQuery(sql);
printResult(rst);
Note that you can use the by-pass feature to execute any statement on a source database that UnityJDBC does not natively support. Experimental results show that the by-pass features adds insignificant overhead compared to calling the source JDBC driver directly. Thus, client code only needs to load and use the UnityJDBC driver directly. This results in more portable code that can be more easily moved between database systems.
When UnityJDBC parses the SQL, you can use table and field references that are prefixed with the database name. This is optional if the table and field names are unique across all databases, otherwise the database name is required. The database name is assigned in the schema file describing the source and does not have to be the same as the system name used by the database system itself. That is, the name can be set by the developer using UnityJDBC.
Multiple source UnityJDBC queries can be used with an INSERT INTO statement to populate a table in the database. This allows a user to write a cross-database query to collect information from multiple sources and then insert the result back into a table in any one of the sources. Currently, the only restriction is that the table that will be inserted into must exist and must be present in the schema file describing the source.
ExampleMetadata.java demonstrates UnityJDBC's support for the
DatabaseMetaData interface. This interface functions exactly
according to the standard with the major difference that metadata is returned for all
databases in the data virtualization rather than from a single database. That is, all your
"integrated" databases really do appear as a single database to your application.
Embedded in the UnityJDBC driver is a complete relational engine. This is required to process cross-database join queries. Most users will not interact with the engine directly, and their only contact with the engine may be to increase the JVM heap sizes for processing large cross-database queries. However, all of the relational operators of selection, projection, and join are available for direct use in your programs. The join algorithms support sources larger than main memory, and allow you the full power of combining ResultSets from multiple databases. It is also possible to explicitly track global query progress on a per operator basis or perform your own optimization of queries after the UnityJDBC optimizer has built an execution tree.
ExampleNoFileConnection.java demonstrates UnityJDBC's ability to be dynamically configured at run-time
including adding, removing, or updating sources. It is possible to dynamically build a virtual database without using XML configuration
files by interacting with UnityJDBC through its metadata API.
Table of Contents
The UnityJDBC SourceBuilder is a simple query utility for cross-database joins and data virtualization. In most cases, you will use UnityJDBC to perform data virtualization with reporting software such as JasperReports and Splunk or query software such as SQuirreL SQL or Aqua Data Studio. Once you have used SourceBuilder to build the virtual source and schema XML configuration files, you use UnityJDBC like any other JDBC driver. This section contains examples on how to install and use UnityJDBC data virtualization in popular software systems.
UnityJDBC is integrated into SQuirreL SQL allowing users to build SQL queries that join data from multiple sources directly within SQuirreL. The multiple source query plugin allows SQuirreL users to create a virtual data source that may consist of multiple data sources on different servers and platforms. The user can enter one SQL query to combine and join information from multiple sources.
Benefits:
-
The multisource plugin powered by UnityJDBC allows SQuirreL SQL to support multiple source queries.
-
No data source or server changes are required.
-
The plugin supports standard SQL including joins, group by, aggregation, LIMIT, and ordering where tables may come from one or more sources.
-
The plugin will perform function translation where a user requests a function that is not supported on a certain source.
UnityJDBC can be installed directly as a plug-in through the SQuirreL SQL plug-in interface. It is also possible to download the UnityJDBC distribution and replace the unityjdbc.jar in the plug-in with the latest from UnityJDBC.
-
Registering the UnityJDBC Driver - By adding a driver.
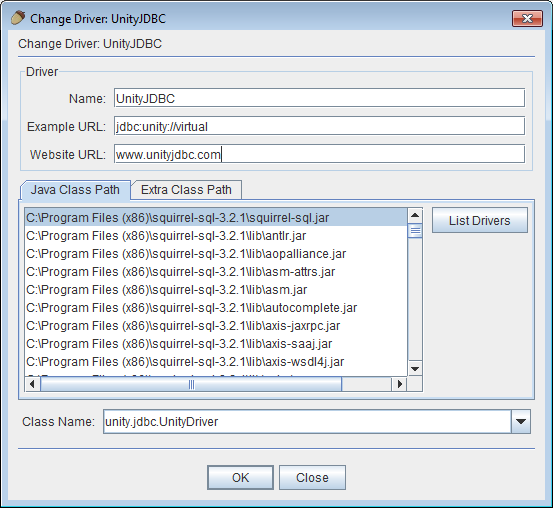
Adding the UnityJDBC to SQuirreL SQL
-
Registering your Data Sources - Register your data sources as usual. In this example, we will perform data virtualization of multiple databases on Microsoft SQL Server, MySQL, Oracle, and PostgreSQL. Any database with a JDBC driver is supported including those accessible using the JDBC-ODBC bridge.
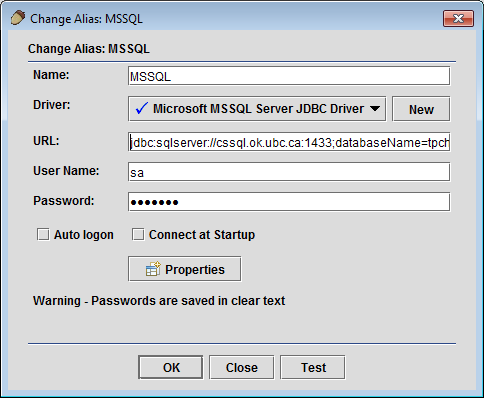
Registering a Microsoft SQL Server Source in SQuirreL SQL
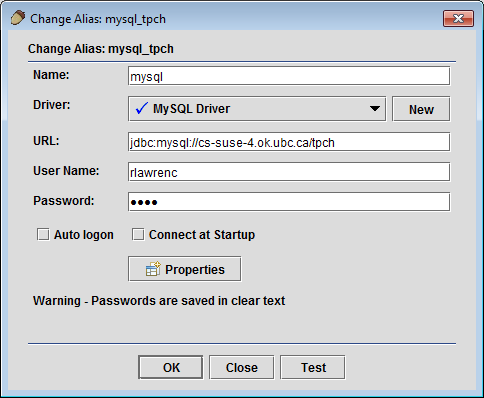
Registering a MySQL Source in SQuirreL SQL
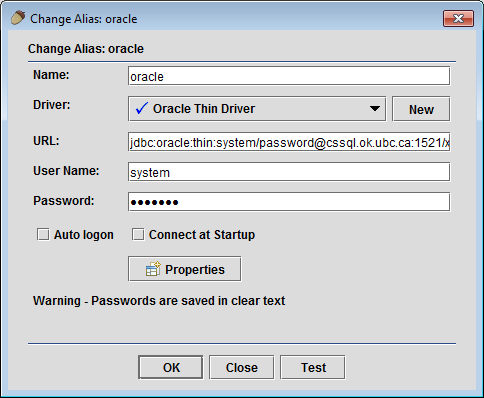
Registering an Oracle Source in SQuirreL SQL
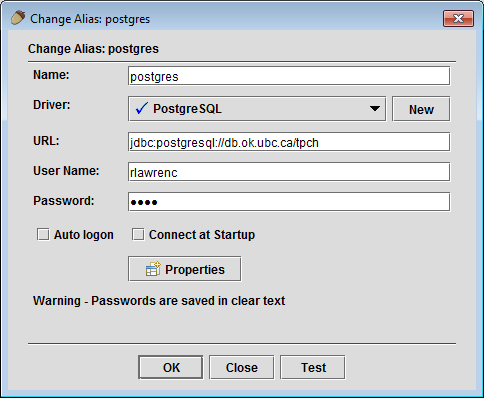
Registering a PostgreSQL Source in SQuirreL SQL
-
Create a Multiple Database Alias - Make sure you have registered the UnityJDBC driver (during installation). Create an alias consisting of virtual sources. The name field can be any name. It does not have to be virtual. If you are using the virtualization embedded into the plugin, the URL is
jdbc:unity://virtual. If you have previously created a data virtualization using the SourceBuilder utility, then the URL should be the file location of the sources file previously created.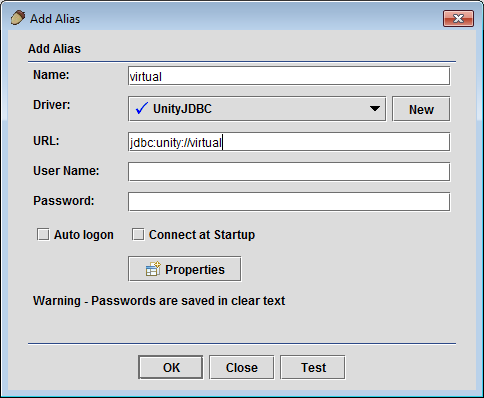
Add a Data Virtualization Alias for Multiple Sources in SQuirreL SQL
-
Add Microsoft SQL Server to Data Virtualization - Right-click on the root object in the object tree, and select
(Virtualization) Add Source. User selects the Microsoft SQL Server source to add to the data virtualization.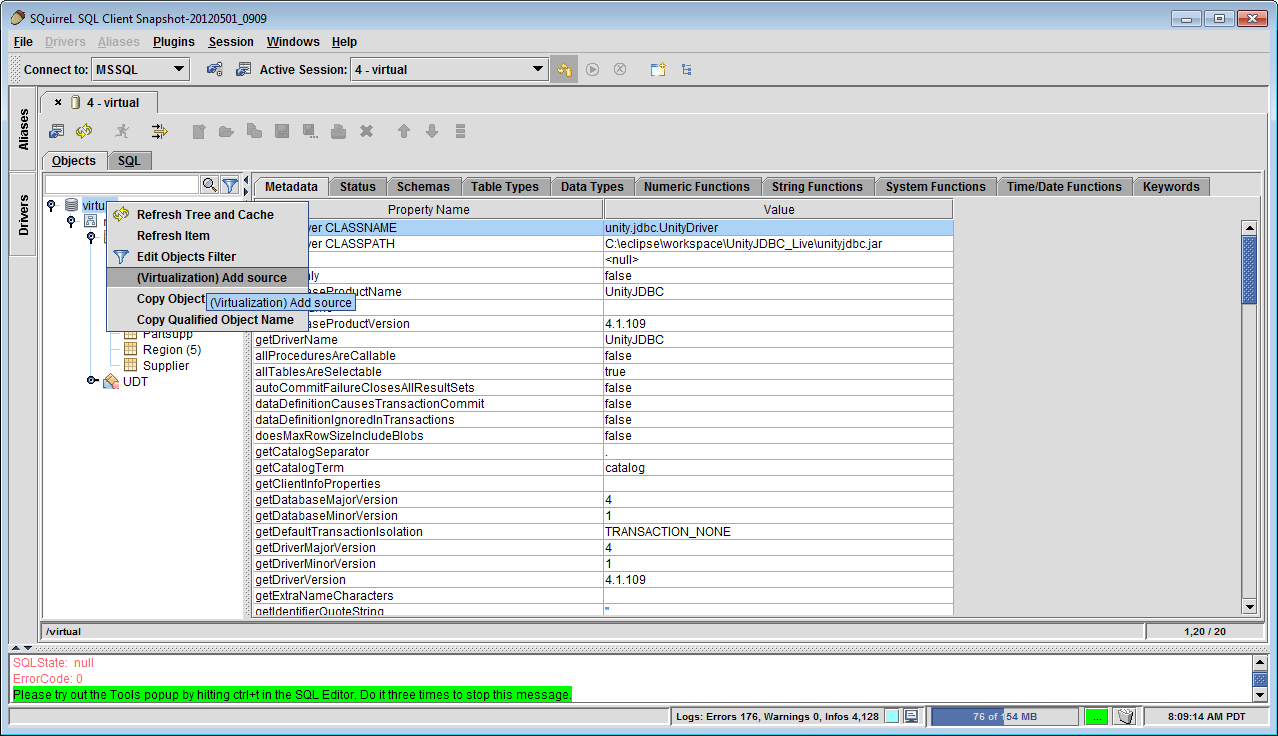
Adding Microsoft SQL Server Source to the Data Virtualization in SQuirreL SQL
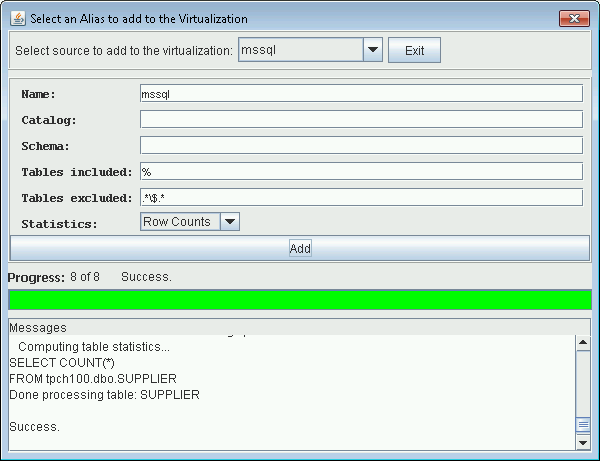
Prompt to add Microsoft SQL Server Source to the Data Virtualization
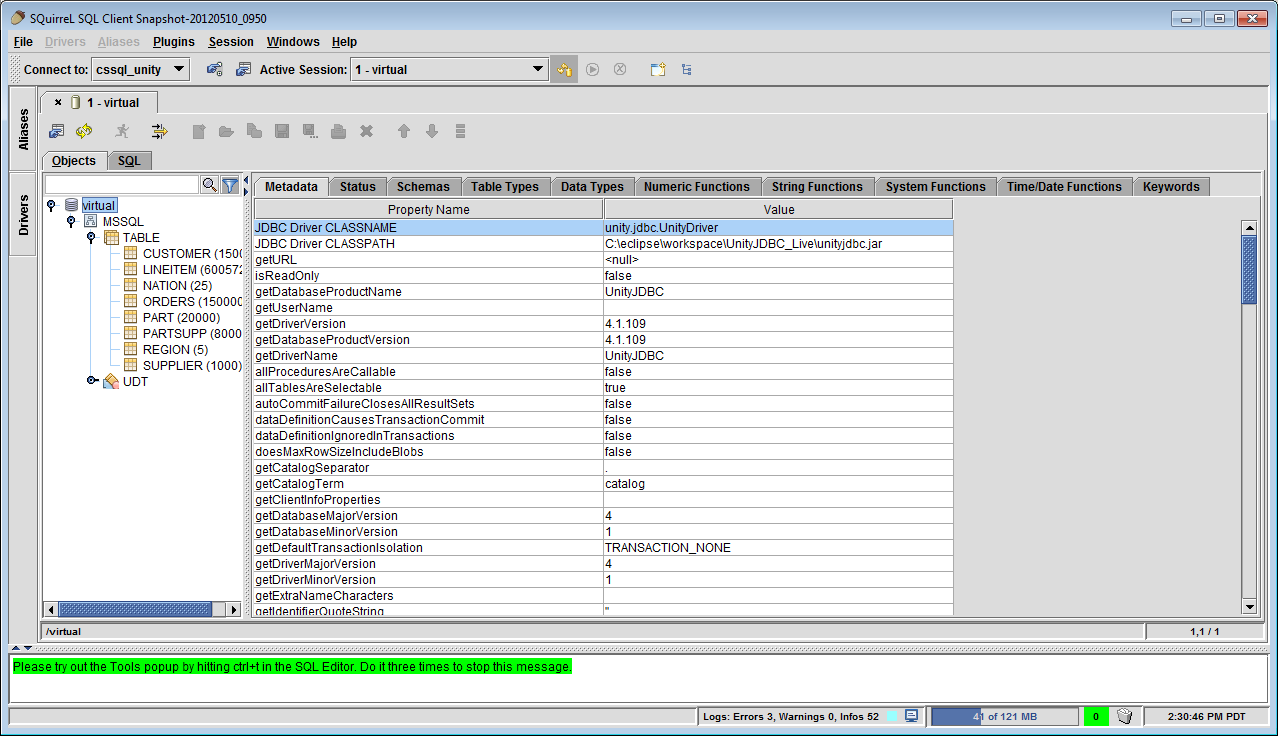
Resulting Data Virtualization
-
Add Oracle Database to Data Virtualization - User can add as many sources as they wish. You can also rename the source in the virtual view. It does not have to be the same as the alias name used by SQuirreL. When adding Oracle sources, make sure to specify a schema so that system tables and tables from all schemas are not extracted.
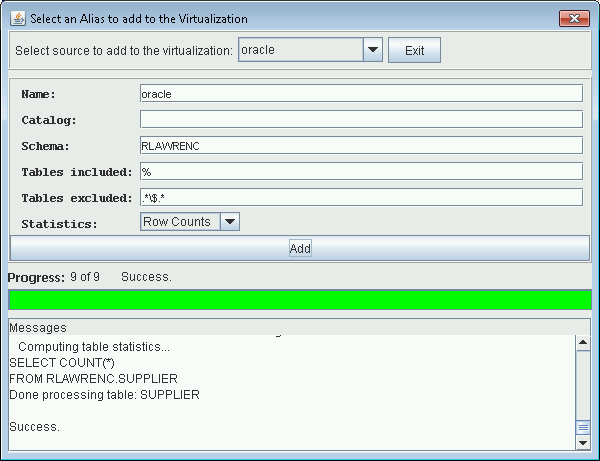
Prompt to add Oracle Source to the Data Virtualization (Note use of SCHEMA).
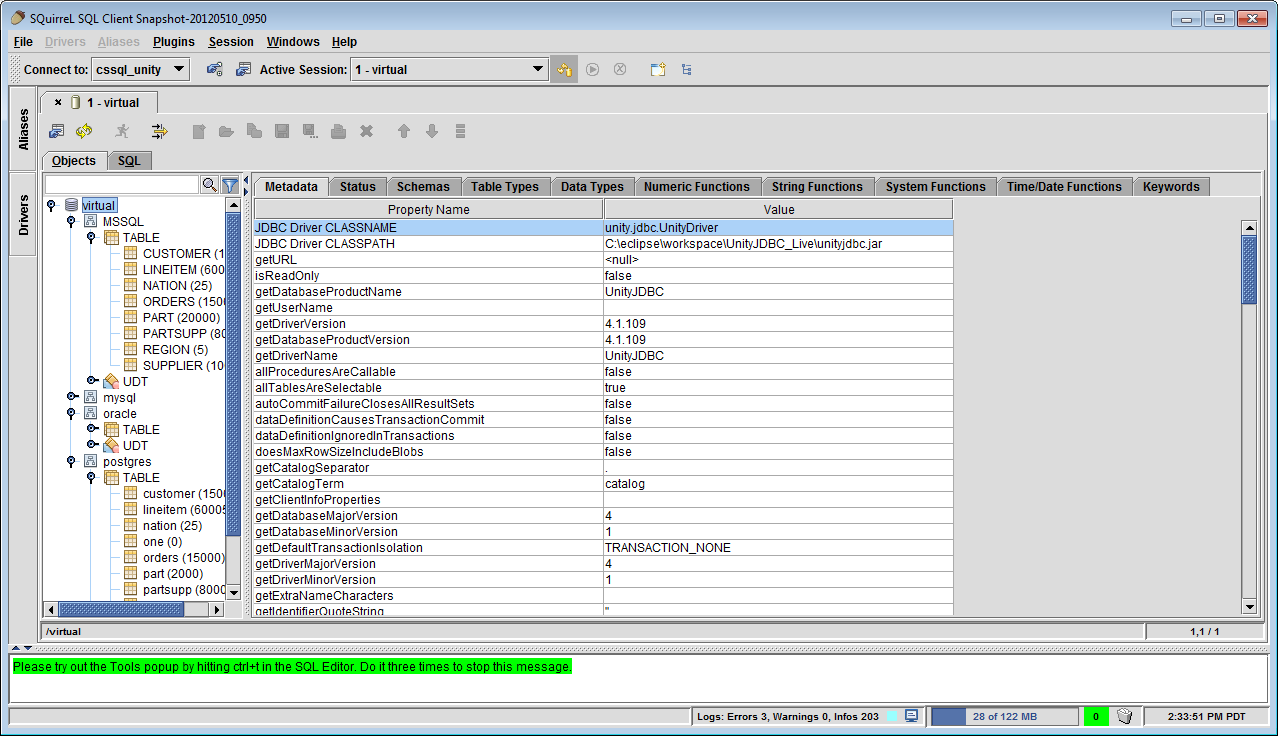
A Data Virtualization in SQuirreL SQL with Databases MySQL, Oracle, PostgreSQL, and Microsoft SQL Server
-
Execute a Multiple Database Query - The user can execute an SQL query that spans multiple sources and get a single result. The virtualization is transparent to the user and SQuirreL. Below is an example of a query that joins two tables in different databases.
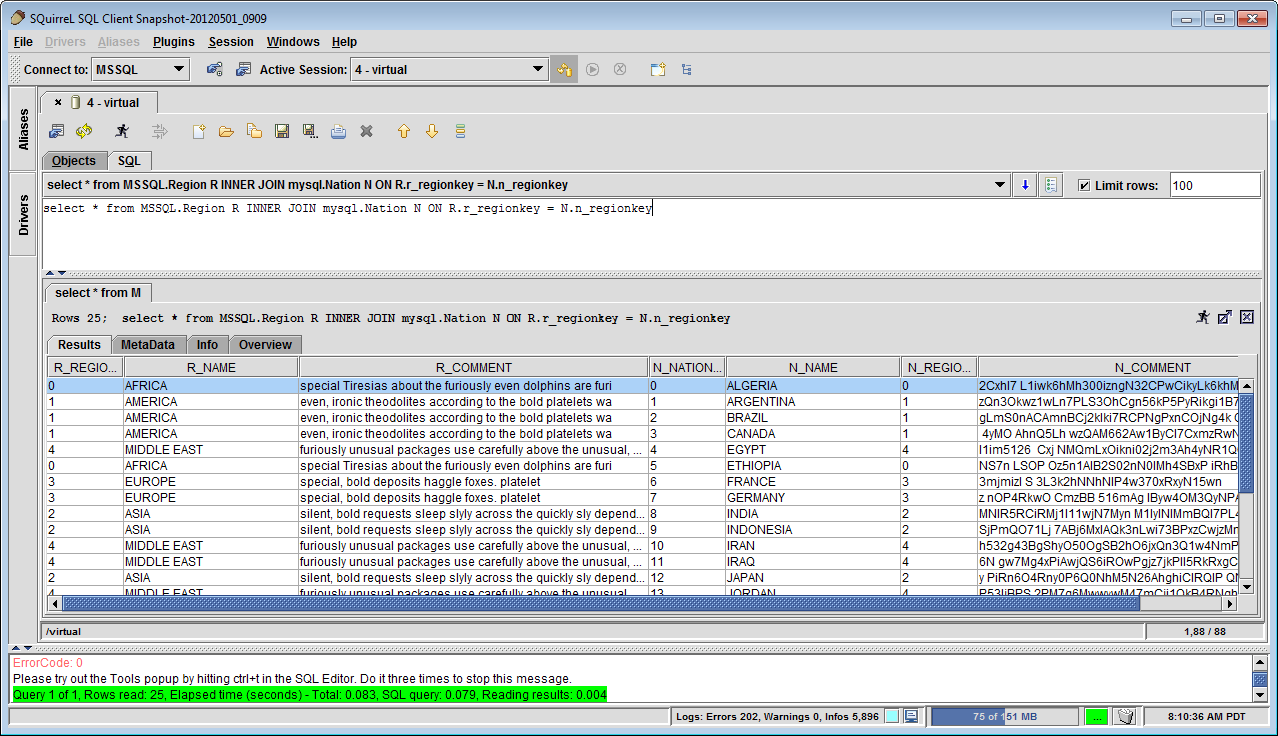
A Multiple Database Query with Join Results Expressed on Previous Data Virtualization
-
Perform SQL Query Translation - The UnityJDBC driver used to perform the virtualization will also translate functions that are not implemented by certain sources. For example, Microsoft SQL Server does not support
TRIM(), but you can do the same result usingRTRIM(LTRIM()). Unity will automatically translate aTRIM()function specified in a MSSQL query to the correct syntax supported by the database.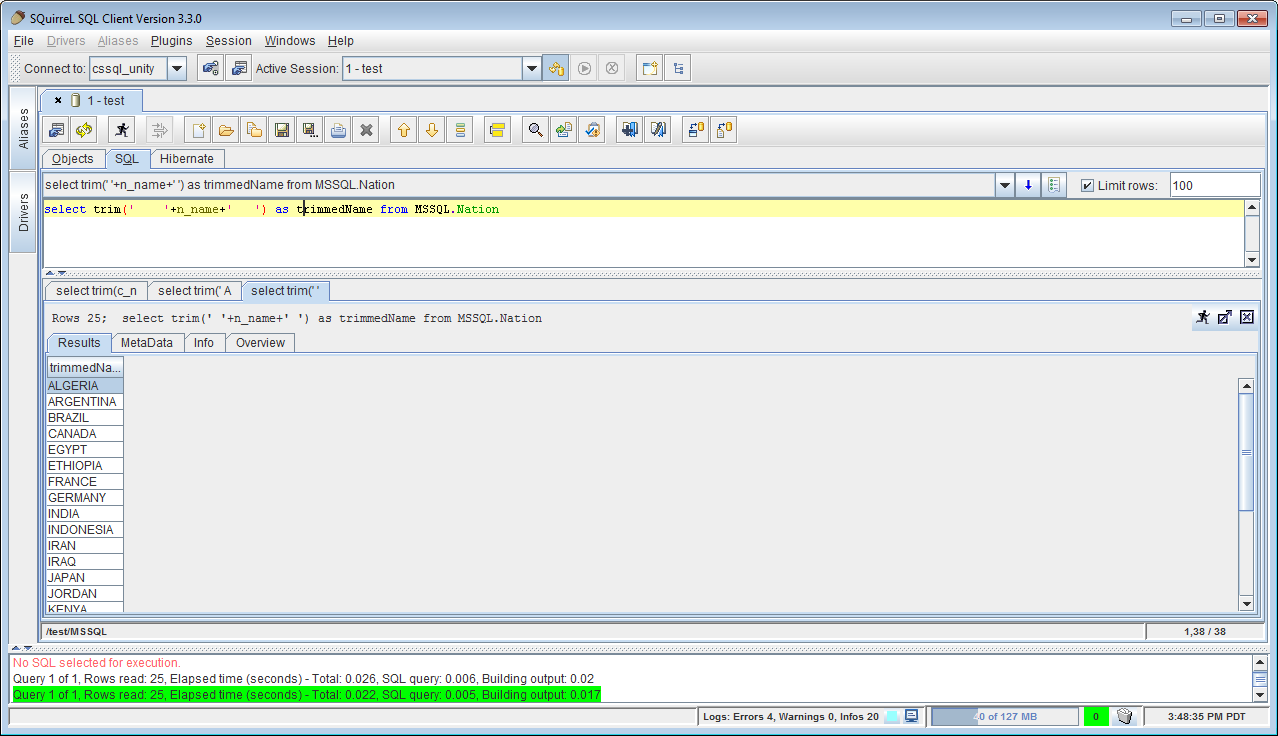
An example of SQL Query and Dialect Translation - Converting TRIM() function for Microsoft SQL Server
The plugin source code, like all of SQuirreL, is released under the GNU Lesser General Public License. The UnityJDBC virtualization driver is released under a commercial license. However, the UnityJDBC driver included in the plugin is fully functioning with no time limits allowing an unlimited number of sources and queries. The only limitation is the size of the result set is limited to the first 100 rows. (Note there is no limit on the number of rows extracted from each source. So select count(*) from table with a 1 million row table is fine as it only returns one result row.) Use LIMIT 100 to get the first 100 results of a query. A full version of the UnityJDBC driver can be purchased as www.unityjdbc.com.
The JasperReports library and community version of JasperReports server does not support data virtualization allowing one SQL query to extract data from multiple databases. UnityJDBC can be used with JasperReports to enable this data virtualization which simplifies the construction of reports, especially reports that would usually use subreports.
Aqua Data Studio can query multiple databases with different SQL queries. However, you cannot query more than one database at the same time in one SQL query. UnityJDBC allows a user to write one query to join, aggregate, and summarize data across any number of databases. It also performs translation of SQL dialects and functions.
Benefits:
-
UnityJDBC allows Aqua Data Studio to support multiple source queries.
-
No data source or server changes are required.
-
UnityJDBC supports standard SQL including joins, group by, aggregation, LIMIT, and ordering where tables may come from one or more sources.
-
UnityJDBC will perform function translation where a user requests a function that is not supported on a certain source.
This example assumes that the installation of UnityJDBC has already been completed. The following is an example of creating sources and executing multiple database queries with Aqua Data Studio.
-
Create a New Source Group - Under File Menu, Select New Source Group.
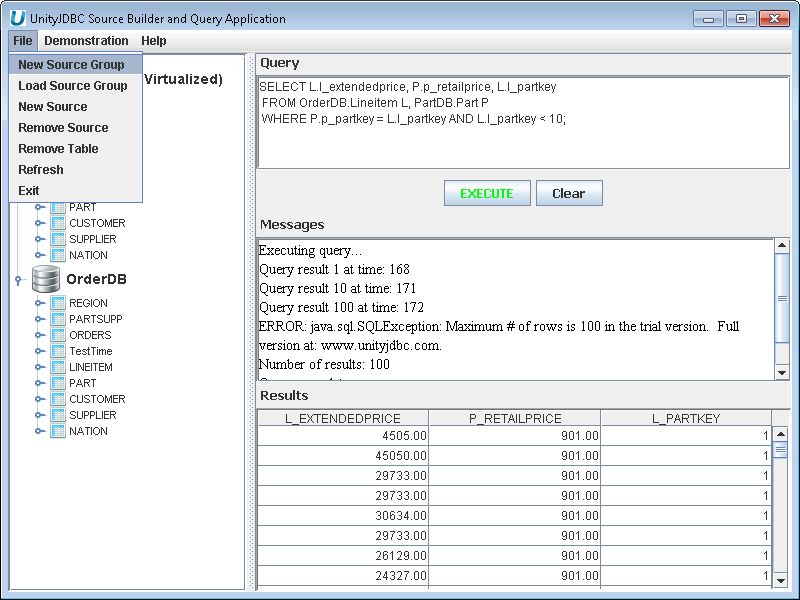
Aqua Example: Creating a New Source Group Data Virtualization
-
Select Sources File Name and Location - Use the default sources.xml or select a file location.
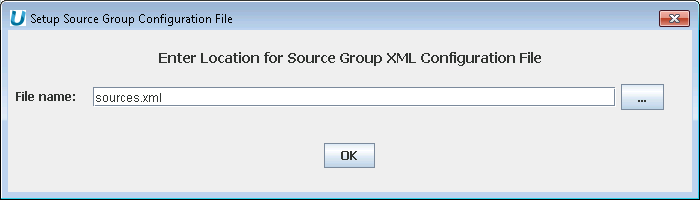
Aqua Example: Specifying a Source File Location
-
Select New Source - Under File Menu, Select New Source.
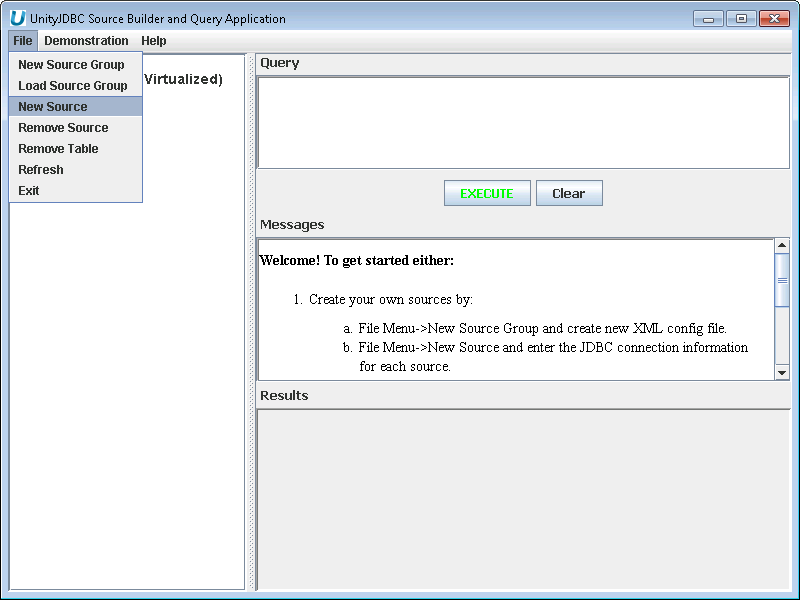
Aqua Example: Creating a New Source
-
Add a Microsoft Database - Enter connection information for Microsoft SQL Server to add it to the data virtualization.
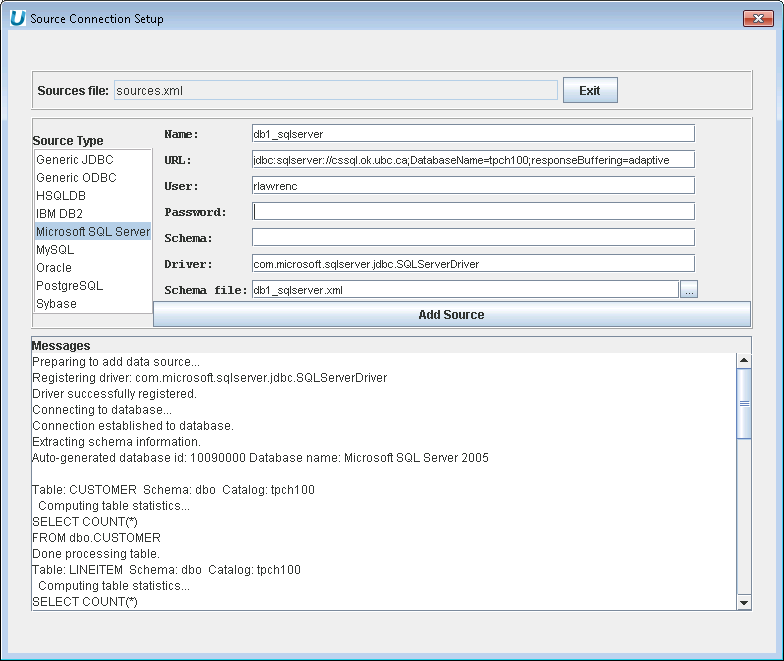
Aqua Example: Adding a Microsoft SQL Server Database to the Data Virtualization
-
Add a MySQL Database - Enter connection information for MySQL database to add it to the data virtualization.
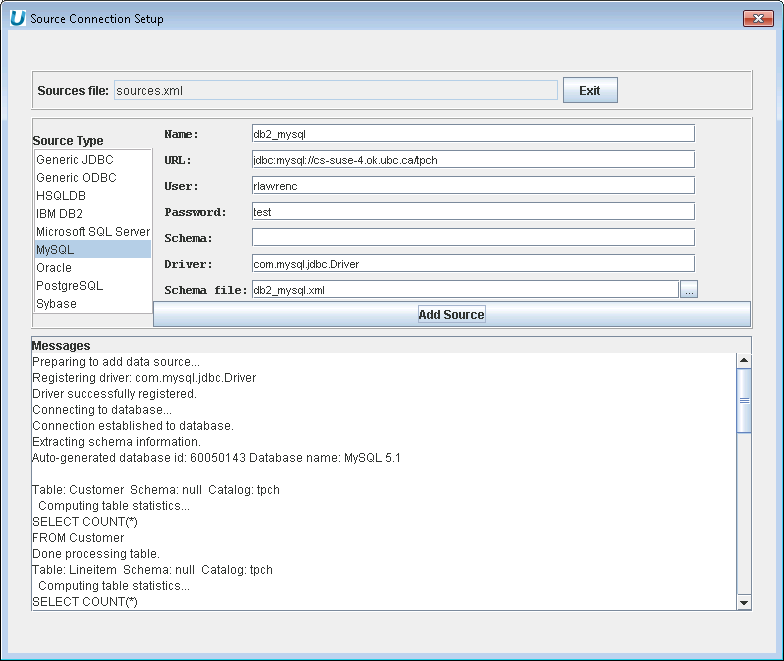
Aqua Example: Adding a MySQL Database to the Data Virtualization
-
Viewing Data Virtualization of Sources - Select Exit to return to the main screen and see data virtualization of MySQL and Microsoft SQL Server sources.
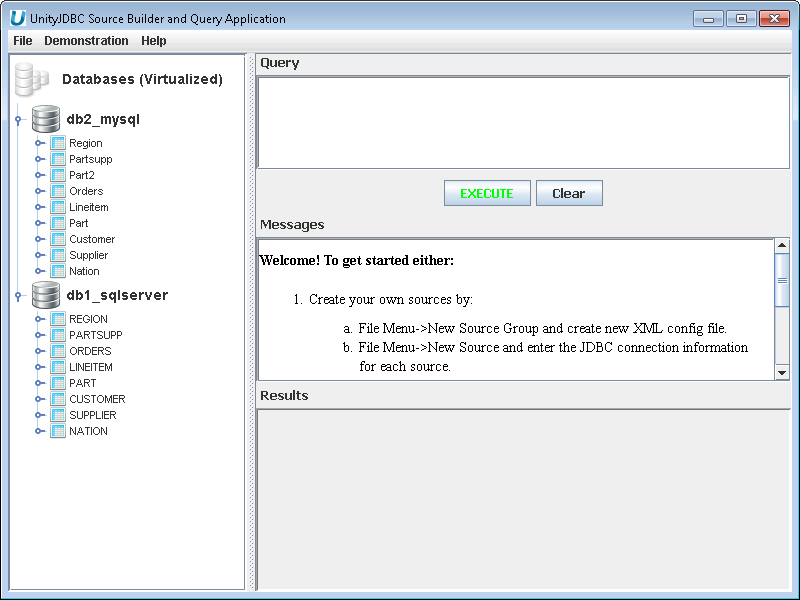
Aqua Example: Resulting Data Virtualization of Two Database Sources
-
Multiple Database Query and Cross-Database Join Example - Type in a cross-database query and execute it to view results.
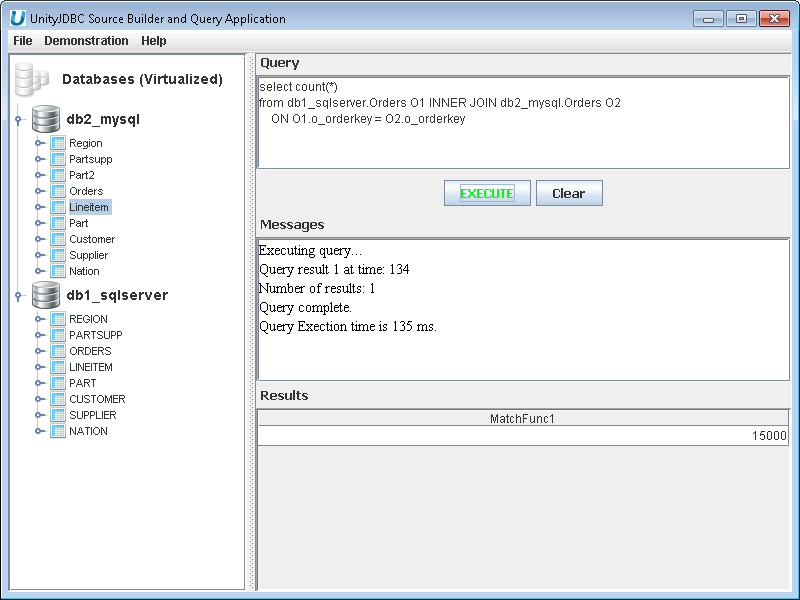
Aqua Example: Executing a Cross-Database Join of Two Databases
-
Finding Sources and Schema Files - Now that the data virtualization is complete, find the sources.xml file and schema files for your sources. The image below shows the default location which would be inside the UnityJDBC installation directory.
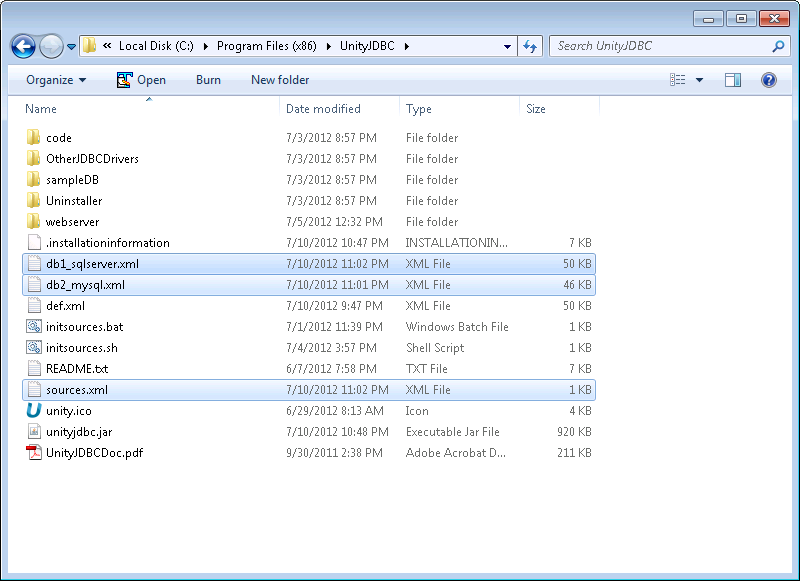
Aqua Example: Finding Source and Schema Files
-
Moving Sources and Schema Files - Optionally, move the sources and schema files to a permanent location. In this example, they are moved to
C:/unityjdbc.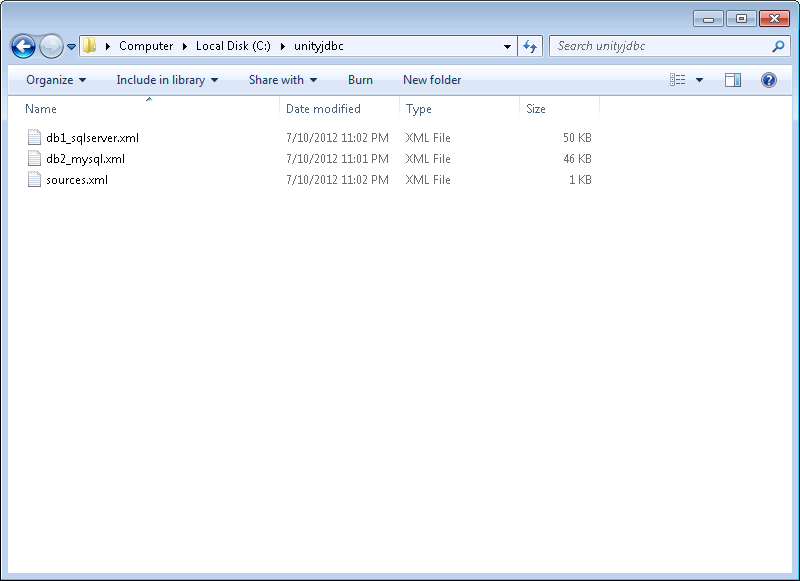
Aqua Example: Moving Source and Schema Files to Another Location
-
Adding UnityJDBC data source to Aqua Data Studio - Copy
unityjdbc.jarand all JDBC drivers for databases intojre/lib/extin Aqua Installation directory.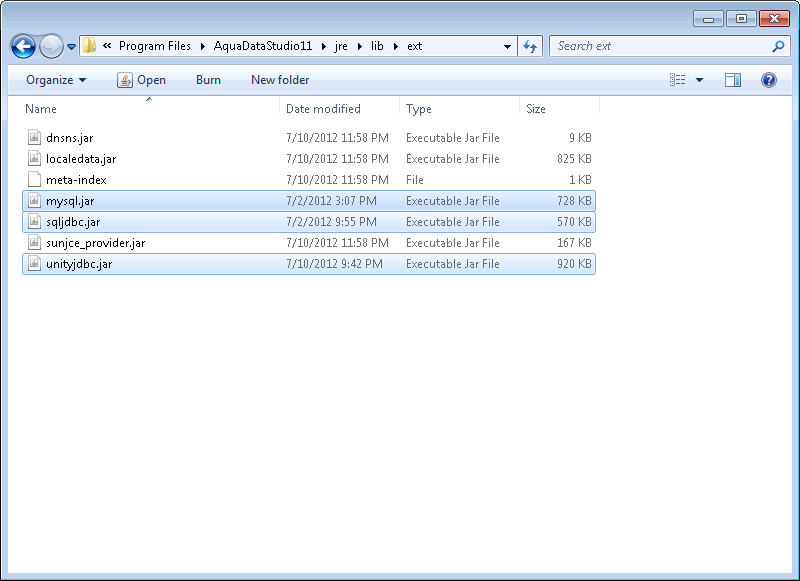
Aqua Example: Installing unityjdbc.jar in Aqua Data Studio
-
Start Aqua and Register a Generic JDBC Source - The configuration information is:
-
Driver:
unity.jdbc.UnityDriver -
URL:
jdbc:unity://<path to sources.xml file>
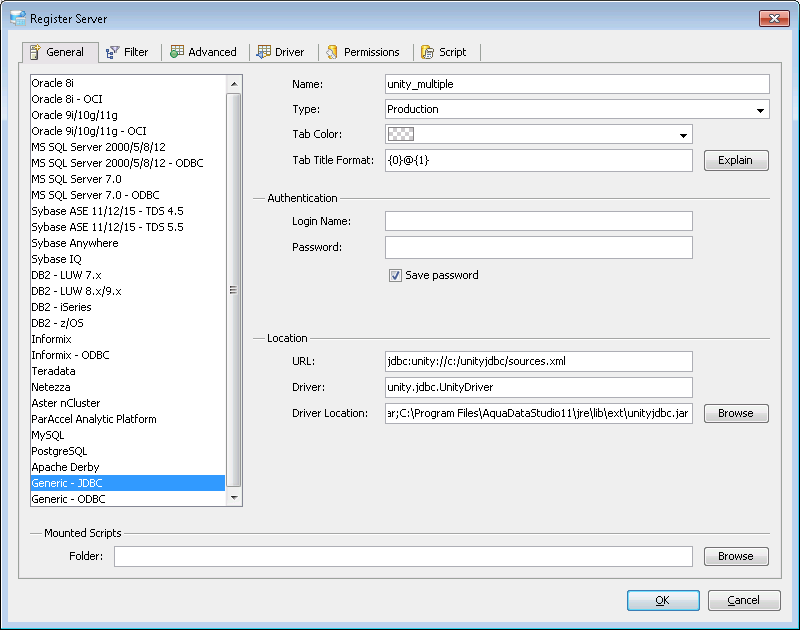
Aqua Example: Adding a UnityJDBC Virtual Data Source in Aqua Data Studio
-
-
Multiple Database Query in Aqua Data Studio - Create a query like usual except it can contain multiple databases.
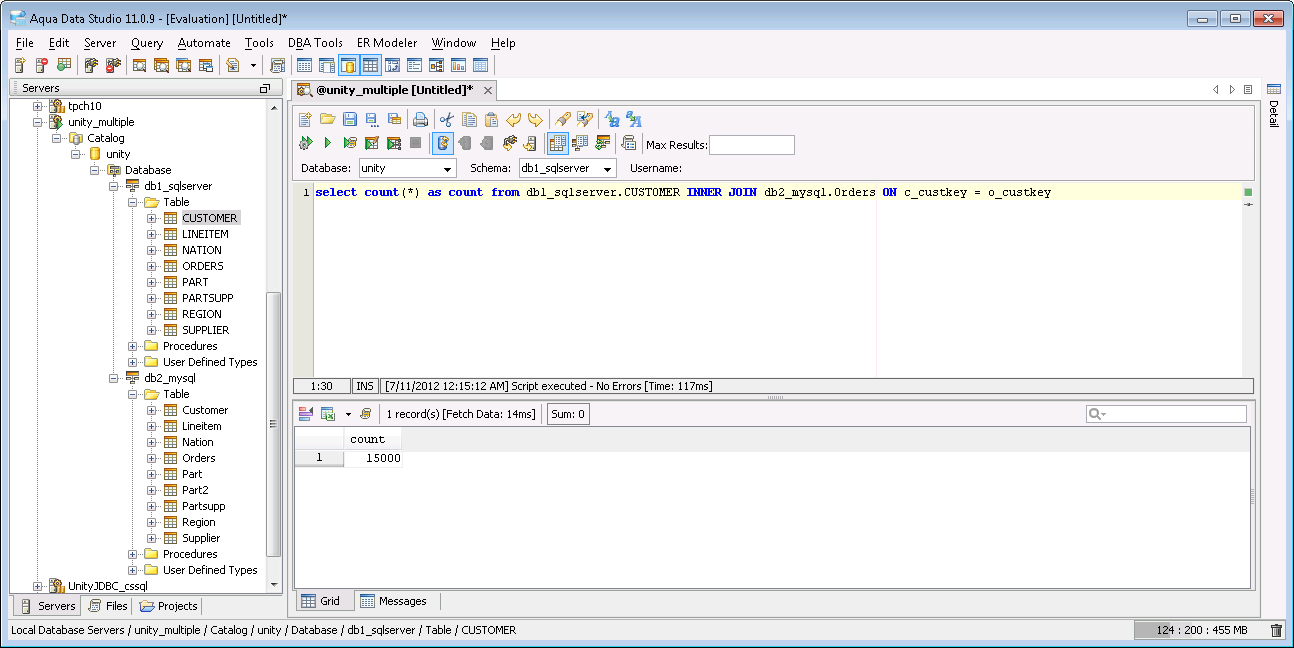
Aqua Example: Executing a Multiple Database Join Query and Displaying Results
-
Function and SQL Dialect Translation with Aqua Data Studio - Forget what functions you can use on each database? No problem – UnityJDBC will translate automatically. This translation is supported for common databases and can be freely extended by user-defined functions and translations for each database dialect.
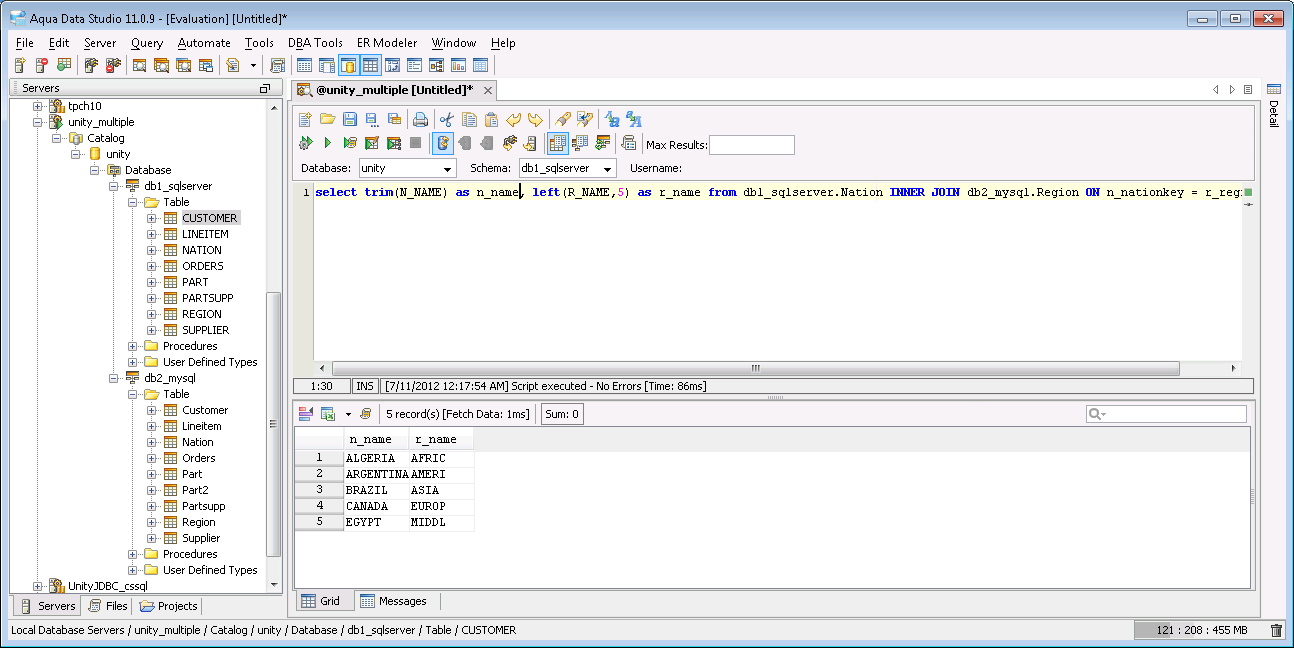
Aqua Example: Performing SQL Dialect and Function Translation
UnityJDBC allows RazorSQL users to create a virtual data source that may consist of multiple data sources on different servers and platforms. The user can enter one SQL query to combine and join information from multiple sources.
Benefits:
-
UnityJDBC allows RazorSQL to support multiple database queries.
-
No data source or server changes are required.
-
UnityJDBC will perform function translation where a user requests a function that is not supported on a certain source.
This example assumes that the installation of UnityJDBC has already been completed, and that the user has already created a data virtualization using the UnityJDBC SourceBuilder. The following is an example of creating sources and executing multiple database queries with RazorSQL.
-
Installing the Jars - Copy the
unityjdbc.jarinto the RazorSQL JRE directory (e.g.C:\Program Files (x86)\RazorSQL\jre\lib\ext). -
Setup RazorSQL - Start RazorSQL. Add a UnityJDBC connection profile under menu
Connection->Add Connection Profile.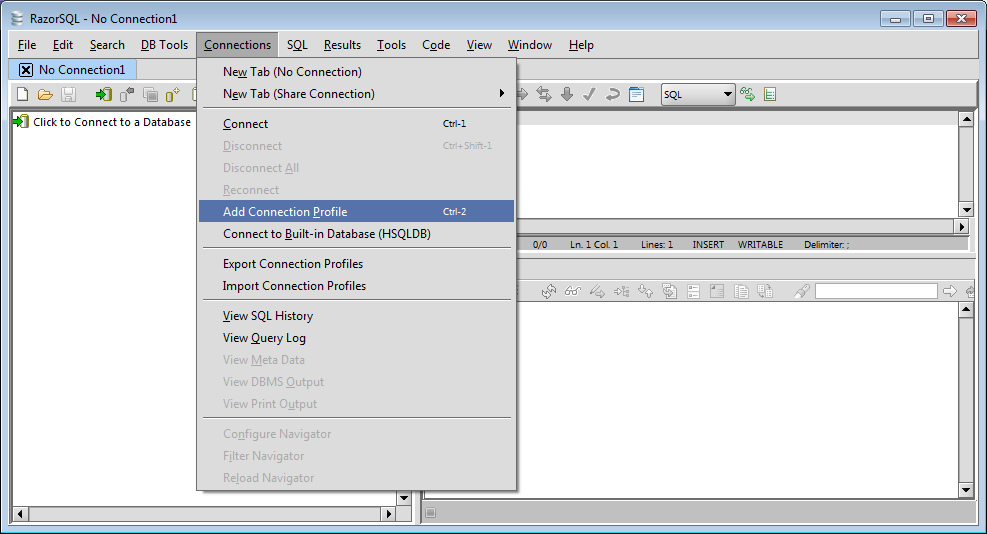
RazorSQL: Adding a New Connection Profile
-
Setup RazorSQL - Part 2 - Select OTHER then press the CONTINUE button.
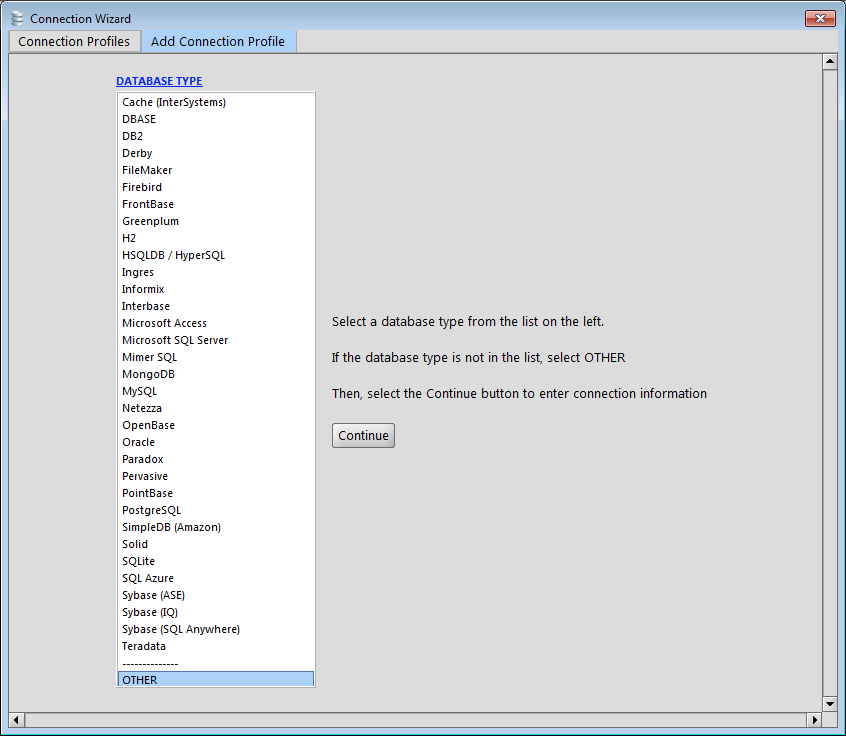
RazorSQL: Adding a UnityJDBC Virtual Connection using OTHER Option
-
Setup RazorSQL Connection Profile - When setting up the connection profile, the profile name can be anything you wish. The driver location is where you just put the
unityjdbc.jar. The driver class isunity.jdbc.UnityDriver. There is no login or password. The JDBC URL is the location of the configuration files for the virtual sources. In this example, we put the filesUnityDemo.xml,UnityDemoOrder.xml,UnityDemoPart.xmlthat came in the distribution in the directoryc:/temp/unityjdbc. You will change this to your source files that you built using the SourceBuilder utility.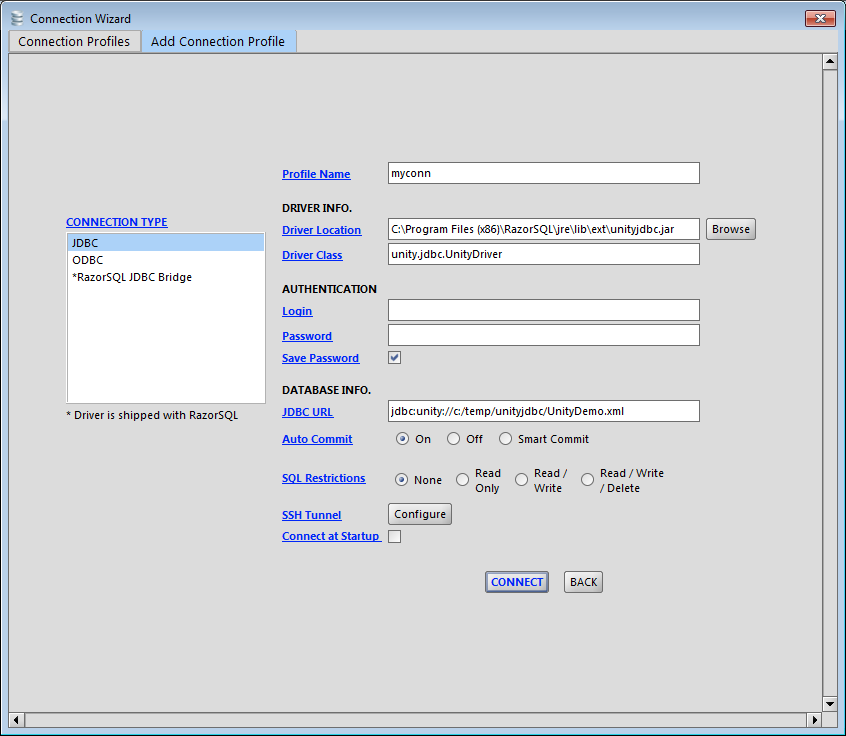
RazorSQL: Creating a UnityJDBC Virtual Connection
-
RazorSQL Multiple Database Connection and Query - Connect to the connection profile. You can then see tables from all your virtual sources and built a multiple database query.
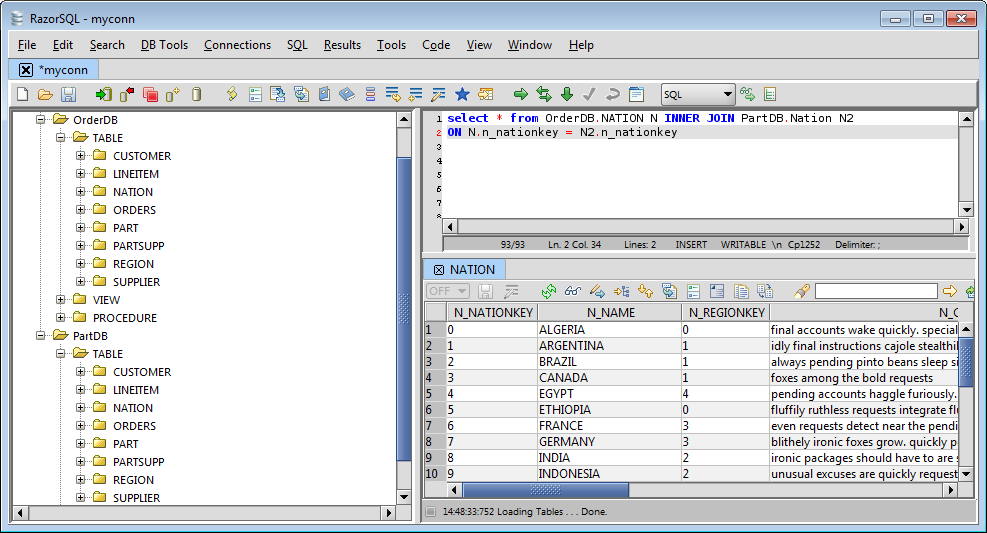
RazorSQL: Executing a Multiple Database Join with UnityJDBC
A few possible setup errors and their resolution:
-
Unable to make a connection - If you do not type the connection string correctly or you have not put the XML files in the right location, you will get the error below. To fix, verify the location of the files.
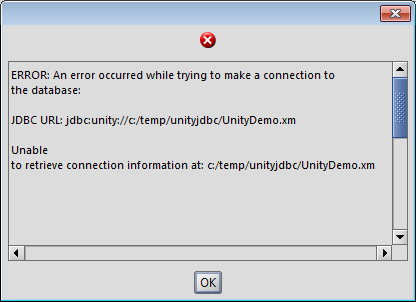
RazorSQL: Error When Unable to Find Sources File
-
Unable to find driver - If you did not put the correct class name or location of the
unityjdbc.jar, you will get the following error. Verify the class name and jar location to resolve.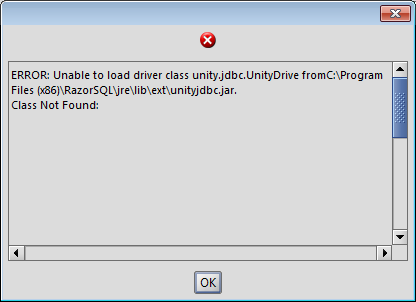
RazorSQL: Error When Unable to Find Driver or Incorrect Driver Class Name
Table of Contents
UnityJDBC supports a cross-database SELECT
statement. The SELECT statement has the standard SQL-92 syntax
and supports WHERE, ORDER BY, GROUP
BY, and HAVING. UnityJDBC supports subqueries on a single database and cross-database including subqueries in the FROM clause and WHERE clause.
entire query is on a single database. SQL functions are supported using a function syntax with parameters rather than
using SQL keywords and syntax. Table and fields often should be prefixed with the database
name they originate from. This database name is provided in the schema file for the data
source.
The standard SQL data types are supported. Since UnityJDBC uses the JDBC drivers provided by database vendors, non-standard data types may not be universally supported.
An identifier is a string used to reference a database, table, or
field. Identifiers follow the standard SQL rules. Since a UnityJDBC query may span multiple
databases, table and field identifiers defined in a data source may not be unique across all
data sources. In which case, the database name should be added to the identifier to create a
unique system-wide identifier. For instance, consider an order database given the name
OrderDB with a table called Orders and fields
id and orderDate. The Orders
table may be referred to using only Orders or
OrderDB.Orders. Similarly, the field id may be
referred to as Orders.id or OrderDB.Orders.id.
Standard aliasing using AS in the FROM and
SELECT clauses is supported. Delimited identifiers are supported by
enclosing in double quotes (e.g. "from" or "my field with
spaces"). Delimited identifiers must be used for SQL reserved words.
Arithmetic operators +, -, /, %, * are supported as well as
generic expressions. Functions are not specified according to SQL
keyword syntax but rather as a function identifier with parameters
similar to programming languages. The format of functions is:
function (param1, param2, ...).
The following comparison operators are available:
Table 6.1. Comparison Operators
| Operator | Description |
|---|---|
| < | less than |
| > | greater than |
| <= | less than or equal to |
| >= | greater than or equal to |
| = | equal |
| != | not equal |
| IS [NOT] NULL | tests if value is NULL |
| IS [NOT] [TRUE | FALSE] | tests if value is true or false |
The following mathematical operators are supported:
Table 6.2. Mathematical Operators
| Operator | Description |
|---|---|
| + | addition (and string concatenation for strings) |
| - | subtraction |
| / | division |
| % | modulus (remainder of integer division) |
| * | multiplication |
The following are a few of the mathematical functions supported. A complete list of functions is available on the web site.
Table 6.3. Mathematical Functions
| Function | Return Type | Example | Result | Description |
|---|---|---|---|---|
| abs(x) | Same as x | abs(-17.4) | 17.4 | Absolute value |
| ceil(x) | Same as input | ceil(-42.8) | -42 | Smallest integer not less than argument |
| exp(x) | Same as input | exp(1.0) | 2.718 | exponential |
| floor(x) | Same as input | ln(2.0) | 0.69314 | natural logarithm |
| log(x) | Same as input | log(100.0) | 2 | base 10 logarithm |
| power(a, b) | double precision | power(9,3) | 729 | a raised to the power of b |
| random() | double precision | random() | random value between 0.0 and 1.0 | |
| sqrt(x) | double precision | sqrt(2.0) | 1.4142 | square root |
The following are a few of the string functions supported. A complete list of functions is available on the web site.
Table 6.4. String Functions
| Function | Return | Example | Result | Description |
|---|---|---|---|---|
| <str> + <str> | String | 'Unity' + 'JDBC' | UnityJDBC | String concatenation |
| ascii(string) | int | ascii('xyz') | 120 | ASCII code of the first character of the input string |
| length(string) | int | length('UnityJDBC') | 9 | Length of string in characters |
| lower(string) | String | lower('JDBC') | jdbc | Convert string to lower case |
| position(search, target) | int | position('J','UnityJDBC') | 5 | Location of search in target (indexed from 1) |
| replace(source, search, replace) | String | replace( 'abUnityabJDBC', 'ab', 'XX') | XXUnityXXJDBC | Replace all occurrences of search string in source string with replace string |
| substring(string, start) | String | substring('UnityJDBC',6) | JDBC | substring starting at position start |
| substring(string, start, count) | String | substring('UnityJDBC,6,2) | JD | substring starting at position start and taking count characters |
| trim(string) | String | trim(' UnityJDBC ') | UnityJDBC | remove leading and trailing spaces from string |
| ltrim(string) OR trim(string, 'LEADING') | String | trim(' UnityJDBC ') | 'UnityJDBC ' | remove leading spaces from string |
| rtrim(string) OR trim(string, 'TRAILING') | String | trim(' UnityJDBC ') | ' UnityJDBC' | remove trailing spaces from string |
| trim(string, ['BOTH', 'LEADING', 'TRAILING'], [<chars>]) | String | trim('aaaUnityJDBCbbb', 'BOTH', 'ab') | UnityJDBC | remove leading, trailing or both from string where characters removed may be optionally specified in <chars> |
| upper(string) | String | upper('jdbc') | JDBC | Convert string to upper case |
Pattern matching is supported using the LIKE operator.
For example, 'abcdef' LIKE 'ab%' is true. The
'%' is used to match one or more characters, and
'_' is used to match a single character.
Data type conversions are performed using the
CAST(x,y) function. The CAST
function takes any object as the first parameter and takes a string
literal representation of the type to cast to as the second parameter.
Note that the type must be put in single quotes as a string literal.
Example:
CAST(45, 'VARCHAR') creates
'45'
Possible type names are: 'VARCHAR',
'CHAR', 'INT',
'FLOAT', 'DOUBLE',
'DATE', 'TIMESTAMP',
'TIME'.
The following are a few of the date functions supported. A complete list is on the website.
Table 6.5. Date Functions
| Function | Return Type | Example | Result | Description |
|---|---|---|---|---|
| CURRENT_TIMESTAMP | TIMESTAMP | CURRENT_TIMESTAMP | 2011-07-06 12:53:45 | Returns the current date. Format: "yyyy-MM-dd HH:mm:ss" |
| CURRENT_TIME | TIME | CURRENT_TIME | 12:53:45 | Returns the current time. Format: "HH:mm:ss" |
| CURRENT_DATE | DATE | CURRENT_DATE | 2011-07-06 | Returns the current date. Format: "yyyy-MM-dd" |
| YEAR | INT | YEAR('2011-07-06) | 2011 | Returns the year of the given date expression. |
| MONTH | INT | MONTH('2011-07-06) | 7 | Returns the month of the given date expression. |
| DAY | INT | DAY('2011-07-06) | 6 | Returns the day of the given date expression. |
| DATEADD | TIMESTAMP | DATEADD('2011-07-06', INTERVAL 3 days) | 2006-07-06 12:53:45 | Allows the addition of a given date field to a datetime expression. Intervals are supported and are translated as necessary for systems that do not support them. |
The following aggregate functions are supported:
Table 6.6. Aggregate Functions
| Function | Argument Type | Return Type | Description |
|---|---|---|---|
| avg(x) | int, float, double precision type | int for integer types, double precision for float/double types | Average of all input values |
| count(*) | N/A | int | Count of number of input values |
| count(x) | any | int | Count of number of non-null input values |
| group_concat(x) | any | varchar | Returns a comma-separated list of all input values. |
| max(x) | any comparable type | same as input | Maximum of all input values |
| min(x) | any comparable type | same as input | Minimum of all input values |
| sum(x) | int, float, double precision type | int for integer types, double precision for float/double types | Sum of all input values |
For queries on a single database, UnityJDBC parses functions and passes them directly to the database engine for execution. Thus, all functions that can be executed at the source are available. UnityJDBC and user-defined functions are used only when applying functions to data after it is extracted from the sources. UnityJDBC will parse queries containing functions that it itself cannot process in its internal database engine. These functions are passed down to the database engine and executed locally. Only functions that require inputs from more than one database are processed in the UnityJDBC database engine. All other functions are passed down to the sources.
UnityJDBC supports user-defined functions (UDFs). Adding your own user-defined
function is easy. There are two types of functions: row functions and aggregate
functions. A row function operates on one row at a time for its data and includes
functions like SUBSTRING() and ABS(). An aggregate
function is used in GROUP BY queries and aggregates an expression
(usually a column) across multiple rows in a group to produce a single value. Examples
include MAX() and COUNT().
To create a row function, you must create a Java class that extends the Function
class. A template example is in the file F_Function_Template.java.
This class must implement a constructor, an evaluate() method, and provide information on
the parameters it requires. Once completed, as long as this function is available in the
CLASSPATH, UnityJDBC will search for it when called. A similar
template is available for aggregate functions,
A_Aggregrate_Template.java. Sample code is provided in the
directory unity/functions.
UnityJDBC has a database of known functions. This database contains information on what functions are supported on each data source. This is how UnityJDBC processes functions:
-
UnityJDBC does not support function - If a function is not in the UnityJDBC database, it is passed down as-is to the underlying source. If the source is able to execute it successfully, the query continues. If not, an error is thrown.
-
UnityJDBC supports function, data source requires translation - If the function requested in the query is not directly supported by the data source (different name, different parameters, etc.), but UnityJDBC contains a mapping in its database, the function is translated to the correct form on the data source and executed on the data source.
-
UnityJDBC supports function, data source does not support function - If UnityJDBC supports the function but not the data source, then the query is optimized to perform as much of the processing as possible on the source, but the function execution is performed internally in UnityJDBC. This way your query can execute on data sources with the help of UnityJDBC that do not support the required functions.
-
UnityJDBC is running with local execution - If the local execution flag is set for the UnityStatement object executing the query, all functions except aggregate functions are executed by UnityJDBC. This setting may be useful to reduce load on the source or to guarantee absolute consistency of function execution across different sources.
The UnityJDBC function database is encrypted and
stored in the unityjdbc.jar. To add user-defined functions to the
function database, create a mapping.xml file in the JRE classpath
(execution directory, etc.) that stores the information on the
function. An example is included in the release and more information
is available on the web site.
UnityJDBC attempts to support most of the SQL standard. If there
is a function or feature not supported, it is possible to use the NP()
function to pass the query string directly to the data source
by-passing UnityJDBC validation. This may be used to support non-standard functions or SQL syntax. Below are several
examples.
Query:
SELECT N1.n_nationkey, NP('OrderDB','n_name','varchar')
FROM OrderDB.Nation N1 WHERE N1.n_nationkey = 1;
Result: (n_name is substituted directly into the query)
SELECT n_nationkey, n_name
FROM Nation N1 WHERE N1.n_nationkey = 1
Query:
SELECT N1.n_nationkey, NP('OrderDB','(select n_name from nation n2
where N1.n_nationkey = N2.n_nationkey)','varchar') as name
FROM OrderDB.Nation N1 WHERE N1.n_nationkey = 1
Result:
SELECT N1.N_NATIONKEY,
(select n_name from nation n2 where N1.n_nationkey = N2.n_nationkey) name
FROM NATION N1 WHERE N1.N_NATIONKEY = 1
Query:
SELECT N2.*
FROM NP('OrderDB',
'(select n_name,n_nationkey from nation)','n_name,n_nationkey') N1,
NP('PartDB',
'(select n_name,n_nationkey from nation)','n_name,n_nationkey') as N2
where N2.n_nationkey < 2 and N1.n_nationkey = N2.n_nationkey;
Result:
// Substitutes subquery for each of the two data sources (OrderDB and PartDB).
// The result of the two subqueries is then joined at the UnityJDBC level.
// OrderDB:
SELECT N2.n_name, N2.n_nationkey
FROM (select n_name,n_nationkey from nation) N2\n WHERE N2.n_nationkey < 2
// PartDB:
SELECT N1.n_nationkey FROM (select n_name,n_nationkey from nation) N1
More information on non-parsed functions is available on the web site.
The SELECT statement supported by UnityJDBC has the following syntax.
SELECT [ALL | DISTINCT ] <exprList>
[FROM <tableList>]
[WHERE <condition>]
[GROUP BY <exprList>
[HAVING <condition>]
[ORDER BY <expr> [ASC | DESC],...]
[LIMIT <expr> [OFFSET <expr>]]
-
An
<exprList>is a list of expressions. Each individual expression<expr>may be a column identifier, a literal constant, or some expression consisting of operators, functions, constants, and column identifiers. Recall that a column identifier may often need to be prefixed by its database name and table name. -
A
<tableList>is a list of table references. Each table reference can be aliased using theASoperator. A table reference may also be a named subquery such asSELECT * FROM (SELECT * FROM T1) AS R WHERE R.val > 50. -
A
<condition>is a boolean condition that may contain multiple subconditions related usingAND,OR, andXOR. -
If the
GROUP BYclause is used, no attributes should be present in theSELECT <exprList>that are not in an aggregate function or areGROUP BYattributes. -
The
HAVING <condition>filters groups and typically should contain only aggregate functions. -
The
ORDER BYclause can order results on any number of attributes in either ascending or descending order. -
The
LIMITclause allows paging of results. TheOFFSETclause determines the first row of the result with the first row numbered as 1.
Some examples using the TPC-H schema follow. The database name for
these examples is 'OrderDB'.
Return all nations with their key and name:
SELECT OrderDB.Nation.n_nationkey, OrderDB.Nation.n_name FROM OrderDB.Nation;
Return the nations and their regions. Only return nations in the region name of 'AMERICA'. Note the use of table aliasing using AS.
SELECT N.n_nationkey, N.n_name, R.r_regionkey, R.r_name FROM OrderDB.Nation as N, OrderDB.Region as R WHERE N.n_regionkey = R.r_regionkey AND R.r_name = 'AMERICA';
Calculate the number of countries in each region. Only return a region and its country count if it has more than 4 countries in it. Order by regions with most countries.
SELECT R.r_regionkey, R.r_name, COUNT(N.n_nationkey) FROM OrderDB.Nation as N, OrderDB.Region as R WHERE N.n_regionkey = R.r_regionkey GROUP BY R.r_regionkey, R.r_name HAVING COUNT(N.n_nationkey) > 4 ORDER BY COUNT(N.n_nationkey) DESC;
The INSERT statement supported by UnityJDBC has
the following syntax:
INSERT INTO <tbl_name> [(<col_name>,...)] VALUES <exprList>;
Specifying column names is optional. An example is below:
INSERT INTO mydb.Customer (id,firstname,lastname,street,city)
VALUES (52,'Fred','Jones','Smith Lane', 'Chicago');
UnityJDBC also supports INSERT INTO ... SELECT
with the following syntax:
INSERT INTO <tbl_name> [(<col_name>,...)] VALUES <exprList> (SELECT <query>);
This is useful for storing query results into another table. Note that this table and all its column must already exist or an error will be returned. Here is an example:
INSERT INTO emptydb.customer (SELECT * FROM mydb.customer);
The UPDATE statement supported by UnityJDBC has
the following syntax:
UPDATE <tbl_name> SET col1=expr1, col2=expr2, ... [WHERE <condition>];
An example is below:
UPDATE Employee SET salary=salary*1.10 WHERE age > 50;
The DELETE statement supported by UnityJDBC has
the following syntax:
DELETE FROM <tbl_name> [WHERE <condition>];
An example is below:
DELETE FROM Employee WHERE salary > 100000;
The EXPLAIN statement supported by UnityJDBC has
the following syntax:
EXPLAIN <query>
The EXPLAIN statement provides an explanation of the how UnityJDBC
will execute a given query include the translated queries to be executed on each source, the
operations performed by UnityJDBC, and the expected cost of each query operation. Using
EXPLAIN is a great way to determine the performance of queries and improve their execution
speed.
You can use methods to by-pass or flow through the driver to
execute an untranslated query directly on a single source. In the
UnityStatement class are these two methods:
ResultSet executeByPassQuery(String dbName, String sql) int executeByPassUpdate(String dbName, String sql)
These methods will execute a query or update on a single source (given by name). The SQL statement provided is not parsed or validated and passed directly to the source driver. There is no overhead in this type of query as it is equivalent to invoking the source's JDBC driver directly.
Table of Contents
UnityJDBC supports the majority of the methods in the
Driver, Connection,
Statement, ResultSet, and
ResultSetMetaData interfaces. UnityJDBC supports the
PreparedStatement interface but not the
CallableStatement interface. UnityJDBC supports
native updates using INSERT,
DELETE, and UPDATE. It is also
possible to use INSERT INTO to insert query results
into another table. UnityJDBC does not support transactions across
databases. Support for other JDBC methods is also limited by the
underlying support of the JDBC driver for each data source. UnityJDBC
requires a JDK of 1.6 or higher.
Table of Contents
UnityJDBC contains an embedded database engine to join the results produced by executing queries on other JDBC-accessible sources. It requires a JDBC driver for each source to be accessed. The UnityJDBC architecture is the result of years of research and development and has been published in numerous technical and research publications.
Embedded in UnityJDBC is a relational database engine and associated operators of
selection, projection, grouping, ordering, and join. You can build your own global query
spanning data sources by combining these operators into an execution tree. In the
distribution is a file called ExampleEngine.java which demonstrates how
to use the engine to build an execution tree. Also in this file is an example on how you can
have Unity parse but not execute a global query. UnityJDBC will return its global query and
execution plan which you can later execute. This feature gives you the opportunity to modify
the global execution plan before execution if desired. It also allows you to track the
progress of a global query at the operator level.
Table of Contents
UnityJDBC is the product of over 10 years of research and development in database integration and virtualization. UnityJDBC was first released in 2006 and commercial support and development has been ongoing since 2011.
Table 9.1. UnityJDBC Release History
| Release Version and Date | Major Features |
| UnityJDBC v1.0 - May 2006 | Cross-database join support, match functions, full optimizer, query by-pass |
| UnityJDBC v2.0 - May 2007 | Connection pools, DataSource connections, more functions |
| UnityJDBC v3.0 - May 2008 | Native INSERT/UPDATE/DELETE, INSERT INTO...SELECT across databases, PreparedStatements, user-defined functions |
| UnityJDBC v4.0 - August 2011 | Database dialect translation, paging using LIMIT/OFFSET, single database subqueries, result caching |
| UnityJDBC v4.1 - June 2012 | Integration with SQuirreL SQL and JasperReports, BLOB support |
| UnityJDBC v4.2 - January 2013 | Memory-optimized query execution engine, EXPLAIN for query plans, subqueries in FROM clause, improved SourceBuilder GUI |
| UnityJDBC v4.3 - June 2014 | Full subqueries, EXCEPT/INTERSECT, implementation of PooledDataSource and ConnectionPoolDataSource, support for MongoDB, TokuMX, Cassandra, and ServiceNow. |
| UnityJDBC v4.4 - May 2020 | Support for Tableau integration for Splunk and MongoDB, performance improvements, improved MongoDB nesting processing |
The following features are planned in coming versions. Version 5.0 will be released in May 2021 with new versions released approximately every year. If you have any feature requests, please e-mail support@unityjdbc.com.
Table 9.2. Planned Features in Coming Versions
| Version | Feature Description |
|---|---|
| 5.0 | Query optimization and performance improvements, improved SourceBuilder user interface |
The following table summarizes the features of UnityJDBC and the version where they were first introduced.
Table 9.3. UnityJDBC Feature List
| Version | Feature Description |
|---|---|
| 1.0 | Cross-database SQL queries for any JDBC source |
| 1.0 | Query by-pass |
| 1.0 | MERGE feature with MATCH functions |
| 1.0 | Embedded relational database engine |
| 1.0 | Source and schema file encryption |
| 1.0 | Support for Applets |
| 1.0 | Support for query results/databases larger than main memory |
| 2.0 | DataSource connections |
| 2.0 | Pooled connections |
| 3.0 | Prepared Statements |
| 3.0 | User-defined Functions |
| 3.0 | INSERT, DELETE, UPDATE on a single source |
| 3.0 | INSERT, DELETE, UPDATE across sources |
| 3.0 | INSERT INTO across sources |
| 4.0 | Paging using LIMIT/OFFSET |
| 4.0 | Query and ResultSet caching |
| 4.0 | Universal dialect and function translation (support for sources missing functions) |
| 4.0 | Single source subqueries |
| 4.1 | Support for BLOBs/CLOBs. |
| 4.2 | Multiple source subqueries in FROM clause |
| 4.2 | EXPLAIN command for query execution information |
| 4.2 | Ability to control tables extracted into data virtualization by inclusion/exclusion patterns |
| 4.3 | Full subquery support including correlated subqueries |
| 4.3 | INTERSECT/EXCEPT |
| 4.3 | MongoDB, Splunk, ServiceNow, and Cassandra support |
| 4.4 | Tableau JDBC integration with support for Splunk and MongoDB |
| 4.4 | MongoDB nested query optimizations |
| 4.4 | Additional SQL functional and translation support |
| 4.4 | Enhanced support and performance for Splunk, MongoDB, and ServiceNow |